
Benchmarking AI Agents for Real Data Science
What Happened When 150 People Used AI Agents to Answer Real Questions Across SQL Tables, Log Files, and 750,000 PDFs


Bryan Bischof, head of AI at Theory Ventures and adjunct professor of data science and AI at Rutgers University, joined the Vanishing Gradients podcast from San Francisco to talk about evaluating agentic systems, dealing with multimodal data challenges, and the future of context engineering.
I recently caught up with Bryan Bischof, who has a deep background in data science, building data and ML teams at IBM, Blue Bottle Coffee, Stitch Fix, Weights & Biases, and Hex.
We discussed the complex reality of evaluating AI agents. We explored how to benchmark agentic systems accurately, the challenges of multimodal data, and what Bryan learned from running a rigorous hackathon (America’s Next Top Modeler) designed to test whether AI agents can truly do the job of a data scientist.
We wrote this post for those who do not have the time to listen to the entire podcast. It captures some of the most useful technical insights from our conversation:
How to build checkpointed evals and use failure funnels to measure agent capabilities.
What the America’s Next Top Modeler hackathon revealed about evaluating AI agents on real data.
Why multimodal data remains one of the biggest challenges for today’s agents.
How trust and verification loops become essential when agents sound convincing but answer the wrong question.
Why objective functions and continuous user feedback are shaping the future of AI evaluation.
You can check out the full episode on YouTube, Spotify, or Apple Podcasts. You can also interact with the transcript directly in this NotebookLM transcript, if you’d like!
👉 Want to build the kind of AI data agents Bryan and I discuss in this article? Registration is now open for Master Agentic Data Science, where you’ll learn how to build production-ready agentic workflows for real data science, from evals and multimodal pipelines to agent harnesses and context engineering. Sign up here and use the code ADSVG10 for 10% off. Explore all our AI courses and workshops here.👈
America’s Next Top Modeler Hackathon: Purpose and Design
Bryan leads an internal engineering team of five at Theory Ventures, an early-stage venture capital firm with a research-driven strategy. Instead of chasing hype, their team conducts deep research to form investment theses and builds internal software to make the firm more successful.
Our conversation centered around an event Bryan recently co-hosted called America’s Next Top Modeler (read his full post-event writeup: The Hunt for a Trustworthy Data Agent). The motivation for the hackathon came from a clear observation: despite the endless excitement on platforms like Twitter and LinkedIn, AI agents are still quite average at solving real data problems.
To test this theory, Bryan designed an event to rigorously benchmark these systems. The structure of the hackathon ran roughly six hours and included:
A live, in-person environment with 150 participants using their choice of AI tools.
A set of highly realistic data science questions that mimicked actual business requests.
A human baseline, a principal data scientist who was explicitly forbidden from using AI, not even autocomplete, to see how traditional methods stacked up.
A training phase of about two hours, where participants received the full dataset and 10 example questions with solutions, so they could check whether their setup was working and calibrate their agents in a feedback loop.
Three scoring rounds of roughly an hour and a half each, with new sets of questions revealed in stages. Participants worked the questions and submitted a CSV per question, which was auto-graded against a reference answer. Bryan staged the reveals deliberately so participants had to trade off between iterating on questions they had already seen and tackling fresh ones.
Unlimited submissions, no penalty for wrong answers. Bryan flags this upfront as a design flaw: it’s the mechanic that ended up shaping participant strategy more than anything else.
Before the podcast, I spent some time testing the training questions myself using Claude Code and Opus 4.6. I quickly chewed through a large number of tokens and only managed to get four or five out of 10 training questions correct, illustrating the gap between theoretical agent capabilities and practical problem-solving.
The Power of Checkpointed Evals and Failure Funnels
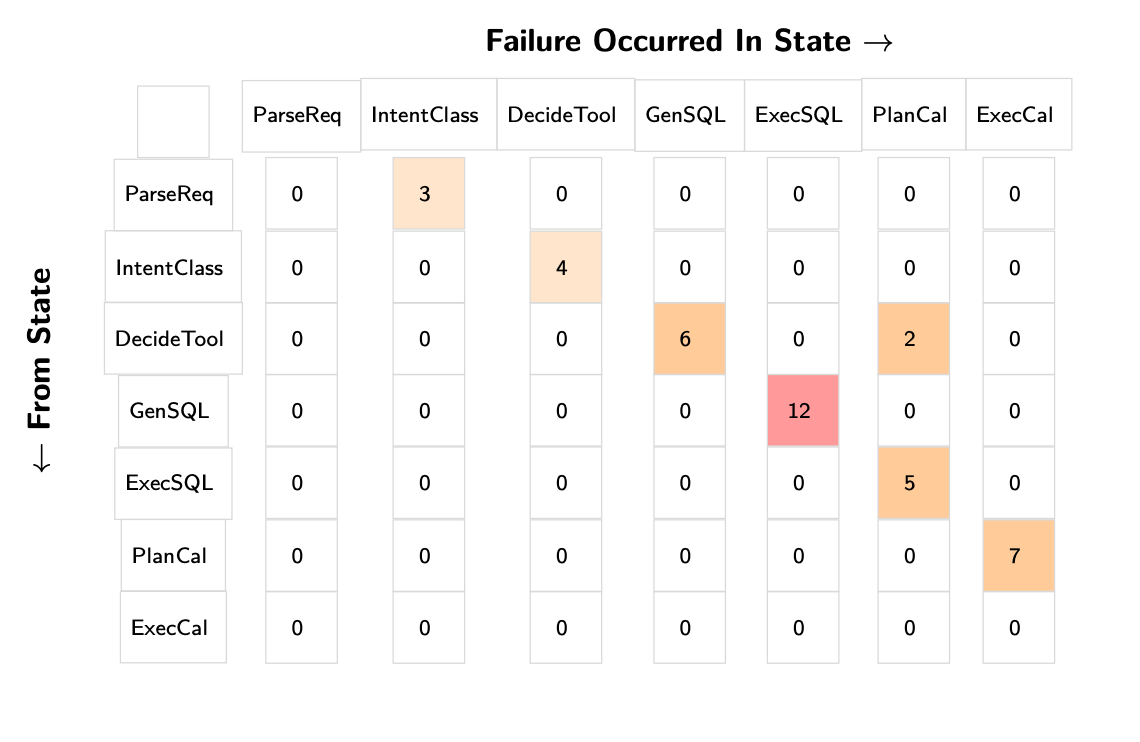
The industry spends a lot of time talking about context engineering and finding the secret sauce for agents, whether that involves complex prompt templates, specific frameworks, or custom Cursor rules. Bryan argues that to truly understand if any of these methods work, you need a highly structured evaluation approach.
His preferred methodology is the failure funnel or checkpointed evals (Hamel Husain has a good walkthrough of this style of evaluating agentic workflows). Instead of a vague vibe check to see if an output looks correct, this approach breaks a complex evaluation down into a series of binary, causally linked questions. This structured approach provides an estimator for capability strength. It dictates that you must evaluate large, essential requirements first and smaller nuances later.
We also discussed how this enables the use of transition matrices. When you iterate on your system, you can map exactly how individual test cases move through your failure funnel. A transition matrix shows you exactly how many examples transitioned from failing at stage one to passing stage three, giving you granular, mathematical visibility into your agent’s improvement.
Real Data is Messy: Working with Multimodal Data
A significant flaw in many existing data benchmarks is that they rely on overly simplistic SQL translation tasks. Bryan went out of his way to design questions that reflected the actual, messy reality of working as a data scientist.
A strong benchmark question requires specific characteristics. It must:
Reflect a real business problem, like identifying inventory issues or understanding seasonal sales
Have only one mathematically verifiable answer
Require precise formatting (like a specific item SKU and a calculated percentage) to allow for automated grading
For example, one question asked participants to identify the item with the strongest seasonal sales pattern, explicitly defining “seasonal” as a scenario where three consecutive calendar months account for more than 50% of annual sales.
To make the challenge authentic, the dataset was strictly multimodal. A data scientist rarely just queries a clean data warehouse. Participants had to navigate:
Tabular data: Clean data stored in Parquet files
Semi-structured data: System logs stored in JSONL formats, representing data that hasn’t yet been ETL’d into the warehouse
Unstructured data: A corpus of 750,000 PDF documents related to the fictional business
Where Agents Break Down
The results of the hackathon clearly demonstrated where agentic systems currently break down. With a room full of highly capable engineers, the median score was 23 out of 65. Bryan noted that he had two primary fears going in: that no one would solve a single problem, or that multiple people would solve everything. The actual distribution landed comfortably in the middle.
The multimodal data proved to be the biggest bottleneck, particularly the unstructured documents.
“Some of the questions required you to aggregate over the PDFs. One question that I think nobody got actually requires you to basically look at every PDF, find out if one particular thing was on that PDF. If so, grab a number from the same PDF and add.”
— Bryan Bischof, 00:39:46
We discussed the architectural solution to this problem. The most effective way to handle this is not by giving an agent raw access to search PDFs. Instead, builders should use patterns like Shreya Shankar’s DocETL or Document Wrangler. By having a language model extract specific structured fields from each document first, you transform a nearly impossible search task into a highly straightforward aggregation task.
Today, agents lack the self-orchestration abilities required to invent this workflow on the fly. While recent projects like OpenClaw show early promise, agents are still at level zero when it comes to intelligently orchestrating other specialized systems without explicit instructions.
Building Trust in Agents, the “Supreme Bullshitters”
A major takeaway from the event was how evaluation design directly influences builder behavior. Because the automated scoring system allowed unlimited submissions without any penalty for incorrect answers, participants defaulted to a maximalist approach.
The most successful strategies involved:
Spinning up general-purpose coding agents like Claude Code
Using heavy manual intervention to poke, prod, and nurse the agents along
Taking as many “shots on goal” as possible to brute-force the correct answer
Bryan pointed out that this exposed a flaw in the hackathon’s design. If there had been a point deduction for wrong answers, participants would have been forced to build verification loops and establish trust in their agents before submitting.
This concept of trust mirrors the real-world dynamic between data scientists and stakeholders (Cimo Labs has a related piece on when your AI metrics are lying to you). Data scientists are expected to be fundamentally truth-seeking. As Bryan put it:
“The reality is agents are the supreme bullshitters. You’ve heard a lot about sycophancy and things like that. It goes actually way deeper than ‘I want to make you happy.’ It’s actually more like they will do things that seem very reasonable... and it’s totally unrelated to the actual question that was asked.”
— Bryan Bischof, 00:51:25
To illustrate, he walked through a hypothetical: an agent analyzing my podcast data builds a beautifully structured histogram of the letter counts of every word spoken in transcripts, then makes up an answer about what topics retain listeners. The work looks impressive and completely fails to answer the underlying business question. Worse, you can’t really interrogate an agent the way you’d interrogate a junior data scientist about how they got there.
We also discussed the distinction between decision science and data science. While A/B testing is pure decision science, much of a data scientist’s job involves iterative problem framing. A vague executive question like, “Does our inventory suck?” takes months of continuous refinement to turn into a tractable, measurable data problem. Agents lack the theory of mind required to navigate this nuanced human loop.
Abstractions in AI: MCP, Tools, and Sub-Agents

The conversation shifted to the evolving language we use to describe agent architecture. Bryan shared his journey from being a skeptic of Model Context Protocol (MCP) to becoming a strong advocate.
Initially, he found early models poor at utilizing MCPs and saw little value in local-only server implementations. His perspective changed when one of the AI engineers on his team framed MCP as a solution to the distribution problem.
At Theory Ventures, different investors use different AI interfaces, Cursor, Claude Code, the ChatGPT desktop app, and Notion AI. An internal MCP acts as a data-modeling layer that securely distributes proprietary data to diverse clients, eliminating the need to provide context.
We also explored the somewhat blurred lines between tools, skills, and sub-agents. Bryan takes a pragmatic view on this terminology:
“A sub-agent [allows you to] hand off a set of instructions... and you expect something to go and do whatever work is necessary to execute. A tool is a set of instructions that you hand off to execute something... There’s only one difference between those two things… how much intelligence is baked into the thing.”
— Bryan Bischof, 01:11:02
Bryan argues that the only value in an abstraction is if it allows you to stop thinking about underlying details. If calling a sub-agent requires a completely different API architecture than calling a web search tool, the abstraction has failed the developer.
This philosophy extends to agent frameworks. During the hackathon, participants using DSPy or LangChain did not noticeably outperform others. Frameworks like DSPy excel at prompt optimization for high-multiplicity, repeatable tasks, but they often add unnecessary friction when dealing with the open-ended, exploratory nature of real data science workflows.
The Future of AI Evals: Objective Functions and Continuous Feedback
We concluded by mapping out the future trajectory of AI evaluation. I proposed an “eval ladder” that reflects how many teams currently operate:
Starting with manual vibe checks
Moving to failure analysis and building golden datasets
Automating checks using regular expressions, fuzzy matching, and code execution
Implementing LLM-as-a-judge for subjective outputs
Building transition matrices for multi-hop systems
Bryan approached the question from a product perspective, drawing on a framework of promise, proof, and production:
Promise: Defining the exact jobs-to-be-done and strict acceptance criteria
Proof: Forming hypotheses about thresholds and running experiments to validate them
Production: Building the necessary scaffolding to make the system reliable
He views the current state of AI evals as a parallel to the historical evolution of software testing. Engineering teams moved from unit tests to integration tests, then to QA, A/B testing, causal inference, and finally, machine learning. Each step was invented because teams acquired more signal than their previous tools could handle.
The future of evaluation lies in moving past static benchmark datasets and trace viewers. The endpoint is setting explicit objective functions for agentic systems and allowing them to converge naturally based on continuous, real-world user feedback.
Key Takeaways
Our deep dive into the hackathon results and evaluation methodologies highlighted several core lessons for AI builders today:
Data problems are coding problems: The most capable agents in the competition were general-purpose coding agents. When you give an agent the ability to write and execute code, it unlocks complex reasoning and data manipulation capabilities.
Unlimited attempts bypass trust: If a system allows infinite retries without penalty, you cannot evaluate the system’s reliability. Penalties force builders to engineer confidence and verification loops into their agents.
Hill-climbing requires rich feedback: Binary “pass or fail” evaluation is insufficient for agent improvement. Bryan’s culinary analogy: he asks me to cook him dinner, I bring him a cubano, and he says “this sucks, do it again.” There’s no chance we converge on a meal he likes. But if he says “I love cubanos, I just hate mustard, and there’s too much mustard on this,” we solve it in one round. The hackathon’s binary feedback meant the participants had nothing to climb on, and because participants had no incentive to give their agents richer feedback either, the loop collapsed at every level.
Master acceptance criteria: The most useful skill for any AI builder today is the ability to translate open-ended goals into precise, easily verifiable acceptance criteria. Mastering this makes you a better prompt engineer, a better system architect, and a better product builder.
Thanks for reading! One final thing… If you want to build the kind of AI data agents Bryan and I discuss in this article? Registration is now open for Master Agentic Data Science, where you’ll learn how to build production-ready agentic workflows for real data science, from evals and multimodal pipelines to agent harnesses and context engineering. Sign up here and use the code ADSVG10 for 10% off. Explore all our AI courses and workshops here.
How You Can Support Vanishing Gradients
Vanishing Gradients is a podcast, workshop series, blog, and newsletter focused on what you can build with AI right now. Over 70 episodes with expert practitioners from Google DeepMind, Netflix, Stanford, and elsewhere. Hundreds of hours of free, hands-on workshops. All independent, all free.
If you want to help keep it going:
Share this with a builder who’d find it useful
 | A guest post by
|