
How to Benchmark AGI
What Breaks in AI Workflows—And How to Fix It

Welcome to Vanishing Gradients!
This issue covers the hard realities of building ML & AI systems: why most notebooks don’t reproduce, what AGI really means, how Instagram’s bold bet on Reels paid off despite early metrics, and how MasterClass invests deeply in ML to move from prototype to production.
You’ll also find upcoming livestreams, lightning lessons, workshops, plus in-person events and LLM course scholarship deadlines. Dive in to see what’s happening next.
Quick links below to what’s coming up in my data/AI life, what just dropped, and how to plug in:
📺 Live Online Events
📩 Can’t make it? Register anyway and we’ll send the recordings.
→ June 19 — Human-Seeded Evals (Live Podcast) with Samuel Colvin (Pydantic, Logfire)
→ June 20 — 10x Your Productivity by Building Personal Agents with MCP with Skylar Payne (AI executive for startups. Ex-Google. Ex-LinkedIn.)
→ June 30 — Workshop: From Images to Agents with Ravin Kumar (DeepMind)
→ July 1 — Lightning Lesson: GenAI’s 4 Pillars with John Berryman (AI Consultant and Builder, Co-Author of Prompt Engineering for LLMs, ex-Github)
🎙 Podcasts & Recordings
→ What Breaks in AI Workflows — Akshay Agrawal (Marimo, ex-Google Brain)
→ How to Benchmark AGI — Gregory Kamradt (ARC Prize)
→ Betting on Reels at Meta — Roberto Medri (Instagram)
→ Building Production-Grade AI Systems at MasterClass — Aman Gupta (MasterClass)
📍 In-Person Events
→ June 16 — Berlin Meetup: Build with AI (Explosion, Native Instruments)
→ June 17 — Berlin Meetup: Agents & Evals (with Rasa)
→ June 24–25 — VentureBeat Transform (San Francisco; use the code 25VanishingGradients for 25% off!)
→ July 7–11 — SciPy 2025 (Tacoma, WA)
🎓 Courses
→ June 22 — Scholarship deadline for the July cohort of Building LLM Applications
📖 Reading time: 12–15 minutes
🎓 Scholarships for the July Cohort: Build LLM Applications
We’re now accepting scholarship applications for the July run of Building LLM Applications for Data Scientists and Software Engineers—our third cohort, and the first timed for the Americas, Europe, and Africa.
The first two cohorts brought together over 150 learners from Netflix, Amazon, Meta, Adobe, Ford, TikTok, and more: all focused on building real, production-grade LLM systems.
The course is taught by me and Stefan Krawczyk (ex-Stitch Fix, LinkedIn, now building agent tooling at Salesforce) and draws on 20+ years of experience building ML and AI systems in production.
✅ Cohort 3 includes:
Access to all Cohort 1 & 2 guest lectures (Moderna, DeepMind, Hex, Honeycomb, Latent Space & more)
Expanded office hours + hands-on workshops
$500 in Modal credits, $300 in Google Cloud & Gemini credits (and more to be announced soon!)
A global, practitioner-led community
📅 Deadline: Sunday, June 22 at 11:59 PM (Anywhere on Earth)
If you know people who might benefit, I’d appreciate you sharing this and engaging with it on LinkedIn.
🎧 What Breaks in AI Workflows—And How to Fix It
Only 4% of notebooks on GitHub reproduce their outputs when rerun. That’s not a user error—it’s a structural problem.
In this new episode, Akshay Agrawal (Marimo, ex-Google Brain) breaks down why hidden state, execution order, and dependency issues quietly break reproducibility—and how Marimo tackles it with dataflow execution, visual indicators, and runtime checks.
We cover:
→ Why reproducibility is a system design problem
→ What breaks in AI/ML workflows at scale
→ What modern tooling should actually do for developers
🎙 Listen to the full episode here (or wherever you listen to podcasts) and/or watch the livestream here.
🧠 How to Benchmark AGI
Gregory Kamradt (President of the ARC Prize Foundation) offers a practical definition of AGI:
“When ARC Prize can no longer come up with problems that humans can do but AI cannot, for all intents and purposes, we have AGI.”
I like this definition because it’s controversial but eminently practical. And a useful frame for tracking real progress.
In our conversation on the Vanishing Gradients podcast, Greg shares:
→ What kinds of tasks still stump LLMs
→ Why even top frontier models still fall short
→ How ARC keeps test data out of training sets—like the Coca-Cola recipe or Gmail’s spam filter
🎙 Listen to the full episode here (or wherever you listen to podcasts) and/or watch the livestream here.
🎙 Betting on Reels—Even When the Data Didn’t Say “Go”
Roberto Medri (VP of Data Science at Instagram) joined High Signal to share the story behind one of Meta’s biggest product bets: Reels.
“We bet big on Reels beyond what you could see in the experimental timeframe.”
Early metrics didn’t show clear upside. But in 2020–2021, the team made a bold call—driven by a culture that prioritized long-term product intuition over short-term A/B results.
We talk about:
→ Why most experiments miss the real signal
→ The hidden costs of A/B test culture
→ How teams scale under uncertainty
→ Aligning product, data, and org incentives
🎙 Check out the full episode here.
🛠 Why MasterClass Invests Heavily in ML—and What That Looks Like in Practice
Aman Gupta (MasterClass) joined me to share how and why MasterClass treats ML as one of the highest-leverage ways to improve their product—and why they’ve invested deeply in building AI systems in-house. He also gave the best breakdown of post-training I’ve encountered (video above):
“Pretraining gives you a document completion engine. Post-training makes it feel like it’s there to help.”
We covered how their team:
→ Layers continual pretraining, fine-tuning, RLHF, and RL with reasoning
→ Uses Metaflow pipelines for evolving post-training infrastructure
→ Measures outcomes through product metrics—not just eval scores
Plus:
→ Why they didn’t settle for off-the-shelf APIs
→ What practical alignment looks like in a branded, voice-based AI product
→ How they think about prompt automation and model feedback loops
🎥 Watch the full livestream here
📅 Upcoming: Livestreams, Lightning Lessons, and Real-World Builds
If you’re working with LLMs and want to go beyond the usual demos, these upcoming sessions are for you. Each one digs into the hard parts—evaluations, agents, workflows—with people building real systems at DeepMind, Logfire, and beyond.
🧪 Human-Seeded Evals (Live Podcast)
📅 June 19 · 4:00 PM GMT+1 with Samuel Colvin (Pydantic, Logfire)
Everyone agrees evals matter. Almost no one does them well. We’ll break down “human-seeded evals”: how to start with a few hand-labeled examples, use LLMs to scale judgment, and learn from real usage at Logfire. Whether you’re building agents or just tired of vibes-based testing—this one’s for you.
🛠️ 10x Your Productivity by Building Personal Agents with MCP (Lightning Lesson)
📅 June 20 · 5:00 PM GMT+1 with Skylar Payne (ex-Google, ex-LinkedIn)
Agents are powerful—until you try to build one. In this 30-minute session, we’ll show how to build tools with FastMCP, guide agent behavior with Mirascope, and wire everything into real workflows—like automating your weekly review. Leave with working code, not just ideas.
🧠 From Images to Agents (Live Workshop)
📅 June 30 · 10:00 AM EDT with Ravin Kumar (DeepMind, Google, ex-SpaceX)
A hands-on session for building multimodal workflows and lightweight, image-driven agents. We’ll extract data from receipts, classify objects, route actions based on image content, and evaluate it all—OCR accuracy, model outputs, and image-based logic. Featuring tools like Gemma (Ollama), Gemini (AI Studio), and Gradio.
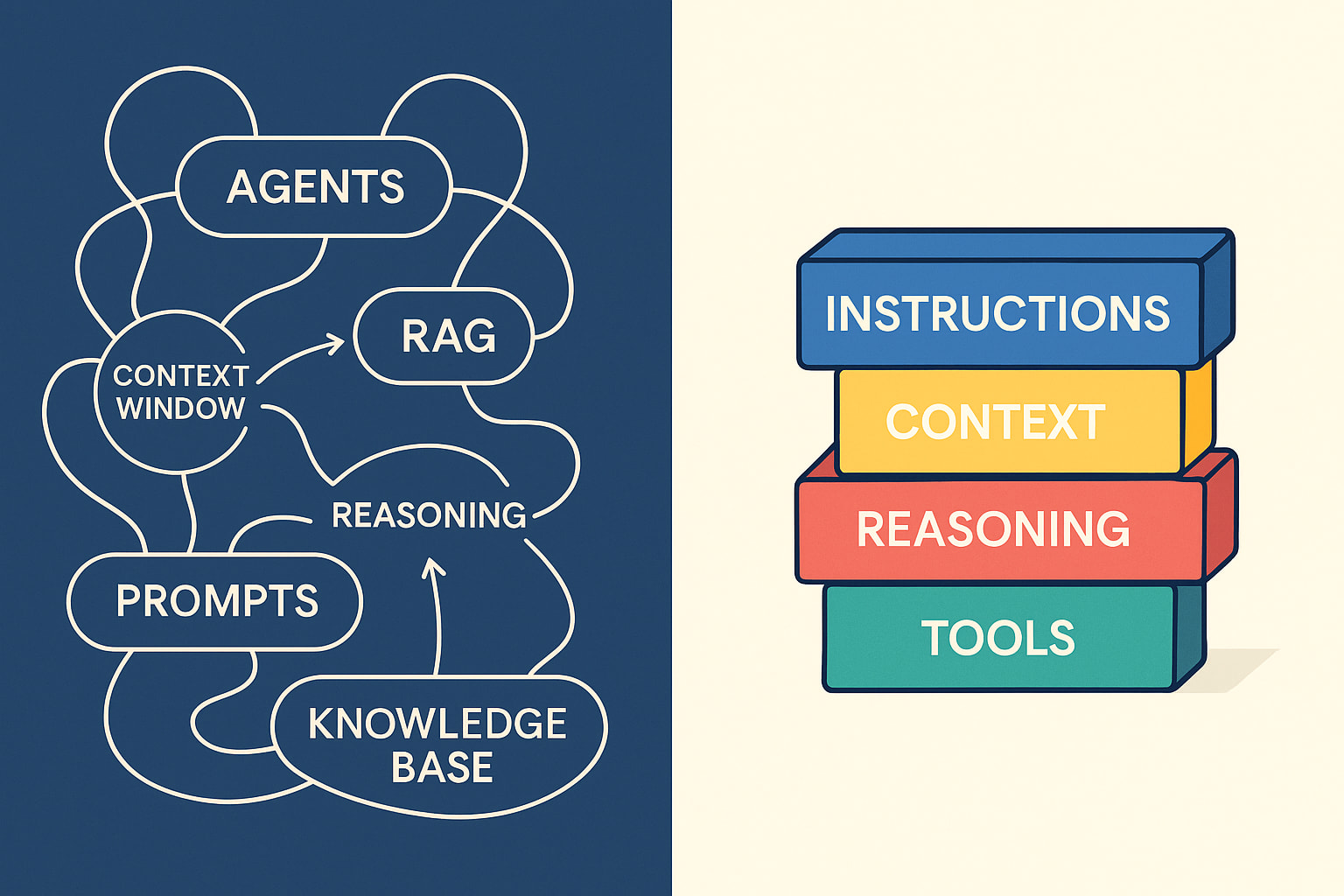
✨ GenAI Systems: The 4 Pillars (Lightning Lesson)
📅 July 1 · 4:30 PM GMT+1 with John Berryman (ex-GitHub Copilot)
GenAI feels chaotic—this session clears the fog. We’ll break down the 4 core building blocks of GenAI systems (instructions, context, reasoning, tools) and show how they support agents, RAG, and full workflows. Once you see the patterns, you’ll start designing your own.
📍 Upcoming In-Person Events

Build with AI — Berlin Meetup
🗓️ Mon, June 16 · 6–9 PM GMT+2
Hosted with Explosion & Native Instruments
Talks from Ines Montani (spaCy) on document understanding, and from me on eval-driven dev and synthetic data flywheels.
Agents & Evals — Berlin Meetup
🗓️ Tue, June 17 · 6–9 PM GMT+2
Co-hosted with Rasa
Alan Nichol (Rasa) on why tool calling breaks agents, and I’ll cover how teams escape PoC purgatory.
VentureBeat Transform — San Francisco
🗓️ June 24–25
Running a workshop and joining panels on building and evaluating AI agents. Hope to see you there.
[Register here and use the code 25VanishingGradients for 25% off!]
SciPy 2025 — Tacoma, WA
🗓️ July 7–11
Workshop: Building LLM-Powered Applications (July 7–8)
Talk: Escaping PoC Purgatory (July 9–11)
Want to Support Vanishing Gradients?
If you’ve been enjoying Vanishing Gradients and want to support my work, here are a few ways to do so:
🧑🏫 Join (or share) my AI course – I’m excited to be teaching Building LLM Applications for Data Scientists and Software Engineers again—this time with sessions scheduled for both Europe and the US. If you or your team are working with LLMs and want to get hands-on, I’d love to have you. And if you know someone who might benefit, sharing it really helps.
📣 Spread the word – If you find this newsletter valuable, share it with a friend, colleague, or your team. More thoughtful readers = better conversations.
📅 Stay in the loop – Subscribe to the Vanishing Gradients calendar on lu.ma to get notified about livestreams, workshops, and events.
▶️ Subscribe to the YouTube channel – Get full episodes, livestreams, and AI deep dives. Subscribe here.
💡 Work with me – I help teams navigate AI, data, and ML strategy. If your company needs guidance, feel free to reach out by hitting reply.
Thanks for reading Vanishing Gradients!
If you’re enjoying it, consider sharing it, dropping a comment, or giving it a like—it helps more people find it.
Until next time ✌️
Hugo