
Why most AI projects fail before they ship (and the eval-driven approach to fix it)
Workshop 1 Wiki from Building AI Applications

What does it actually take to build AI software that works in production? Not just a demo, production. In Workshop 1, we broke down the foundations: evaluation-driven development, the Build→Deploy→Monitor→Evaluate cycle, and why most AI projects fail before they ship.
Yesterday, we had our first workshop of the final cohort for Building AI Applications for Data Scientists and Software Engineers. In addition to our course reader, we build a course wiki alongside the course in real time to aid learning and wanted to share some of the Workshop 1 wiki with you.
Below is content from our course wiki: denser than my usual posts, but hopefully useful as reference material.
👉 Join our final cohort of Building AI Applications for Data Scientists and Software Engineers. All sessions are recorded so don’t worry about having missed any. Here is a 25% discount code for readers. 👈
Welcome & Orientation
What’s This Workshop About?

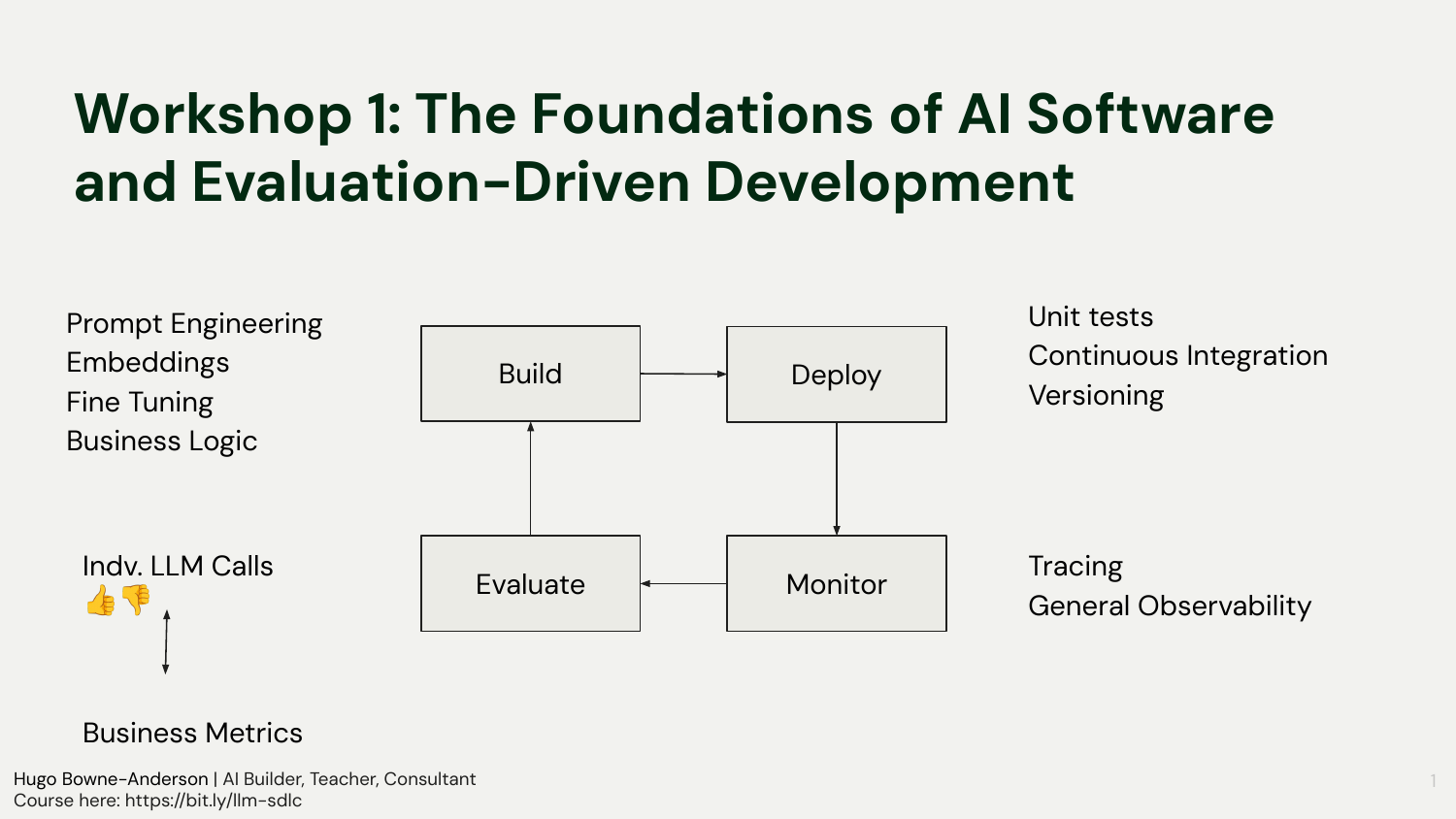
This workshop introduced the problem of AI proof-of-concept purgatory and set up an evaluation-driven approach to building reliable LLM applications. It covered an AI-specific software development lifecycle, practical evaluation levers, hands-on building of a minimal PDF query app with logging, and deployment to production using Modal, plus credits activation.
It paired conceptual framing (POC purgatory, first principles, iterative evaluation) with hands-on work (GitHub Codespaces, a minimal RAG demo with LlamaIndex, a quick Gradio UI, logging to SQLite and exploring traces with Datasette), and closed with a deep dive into Modal’s deployment model and $500 credits for all students.
Foundations of AI POC purgatory: why demos fail in production, and how abstraction hides prompts and traces
Evaluation-driven development: levers for improvement, micro vs macro metrics, and an AI-specific SDLC
Context engineering and RAG: chunking, embeddings, and data preparation quality as major performance drivers; default prompts, hidden embeddings, and “show me the prompt”
First principles: inputs/outputs, knobs, non-determinism (double entropy), logging/tracing, domain-expert feedback, fast iteration
Non-determinism: repeated identical queries yield different outputs; implications for testing and iteration
Hands-on building: minimal RAG-style PDF query app; front-end with Gradio; text extraction with PyMuPDF; logging to SQLite; exploration with Datasette; run LlamaIndex quickstart across providers
Q&A: when not to use LLMs, classic checks vs LLM judges, cost/latency, interpretability
Deployment to Modal: secrets management, image and container lifecycle, verifying a running production app; functions vs sandboxes, images, concurrency, ASGI serving, secrets, examples, and credits
Logistics: Discord-first communication, Codespaces for a shared environment, credits activation and usage
Homework: rebuild without LlamaIndex using direct LLM API calls and prompt logging; construct and log the full prompt
Timeline
[00:00:00] Opening and introductions
[00:12:50] Course logistics, communications, tools, sponsors, schedule
[00:28:31] Conceptual framing: AI Proof-of-Concept purgatory
[00:32:44] RAG basics and early framework failure modes
[00:39:22] Evaluation framing and iterative loop
[00:42:49] First principles and AI SDLC overview
[00:54:46] Q&A: when not to use LLMs; costs, latency, interpretability
[01:07:41] Hands-on: GitHub Codespaces environment and API keys
[01:14:25] Hands-on: LlamaIndex quickstart with OpenAI/Claude/Gemini
[01:20:14] Hands-on: Gradio UI, logging to SQLite, tracing with Datasette
[01:28:52] Homework briefing
[01:31:00] Guest talk: Modal overview and wrapper walk-through
[01:47:12] Guest Q&A: examples, hosting LLMs, credits
[01:58:24] Post-session Q&A: speech-to-speech pipelines with NIM
Framing the Course

Course aims: practical, first-principles approach, with foundations and evaluation front and center
Workshop flow: conceptual segment, Q&A, break, then live building and deployment
Community support via Discord and Builders in Residence for Q&A and optional clubs
The session opened by orienting participants to the goal of building reliable AI-Powered Software and setting expectations for the session flow. The agenda included an initial conceptual segment on foundational ideas and why evaluation is necessary, followed by a hands-on portion to build and deploy a working application.
“In the first workshop, we’re going to be talking about the foundations of LLM software and evaluation-driven development.”
Upcoming workshops include:
Workshop 2: LLM APIs, Prompt Design & Reliable Outputs. LLM APIs, 7 principles for effective prompting, reliable outputs and guardrails, API levers and knobs, memory for stateless systems.
Workshop 3: Evaluation, Iteration & Observability. Why you need evaluation, micro to macro evals, and the three stages: vibes, failure/error analysis, and automated evaluation with LLM judges.
Workshop 4: Testing AI Apps in Dev and Prod. Dev/test/prod loops and CI/CD alignment, pytest primer, tracing and telemetry, frameworks, guardrails in testing.
Workshop 5: Retrieval (Augmented Generation) & Context Engineering, & Agentic RAG. Retrieval and RAG, context engineering, agentic RAG, evals for information retrieval systems.
Workshop 6: Building AI Agents. LLM workflows vs agents, building the agentic loop, when to use agents and when not to, evals for agents, the two cultures of AI agents.
Workshop 7: Multimodal and Multi-Agent Systems. Multimodal AI, multimodal retrieval, multi-agent systems, deep research with multi-agent systems, context engineering for agents.
Workshop 8 Part 1: Fine-Tuning Foundation Models for AI Systems. What fine-tuning is, when not to use it, when to use it, frameworks for fine-tuning.
Workshop 8 Part 2: Production Deployment Patterns. Production case studies, the API call mental model, modularity and SDLC considerations, MCP vs A2A, long-running agents.
We’ll also have live guest sessions with industry leaders like Sebastian Raschka (LLM Research Engineer), John Berryman (Arcturus Labs, Early Engineer on Github Copilot), Ines Montani (spaCy, Explosion AI), and Doug Turnbull (led Search at Reddit & Shopify)
Tools We’ll Use & How We Work Together
Focus on workflows, iteration, non-determinism, observability, and evaluation rather than tool-chasing
Discord-first for all conversations and support; Codespaces, GitHub, and Google Drive for materials and code
Sponsors: credits for Modal, Pydantic Logfire, Chroma Cloud, and Prodigy
Cadence: two-hour workshops, guest sessions, optional Builders Clubs, and asynchronous access to recordings
The course prioritizes systems thinking over plug-and-play recipes. Participants were asked to lean into non-determinism and logging from day one, use Discord threads for questions and debugging, and collaborate in a shared cloud dev environment to avoid dependency conflicts. The learning arc includes prompt engineering, evaluation and observability, testing in development and production, RAG, agents, multimodal systems, and fine-tuning, with a recurring emphasis on iteration guided by data.
“This course is a practical, first-principles approach to building AI-powered applications. We’re going to focus on workflows, iteration, and hands-on development”
[00:14:40]
Section 1: Slides
AI Proof-of-Concept Purgatory
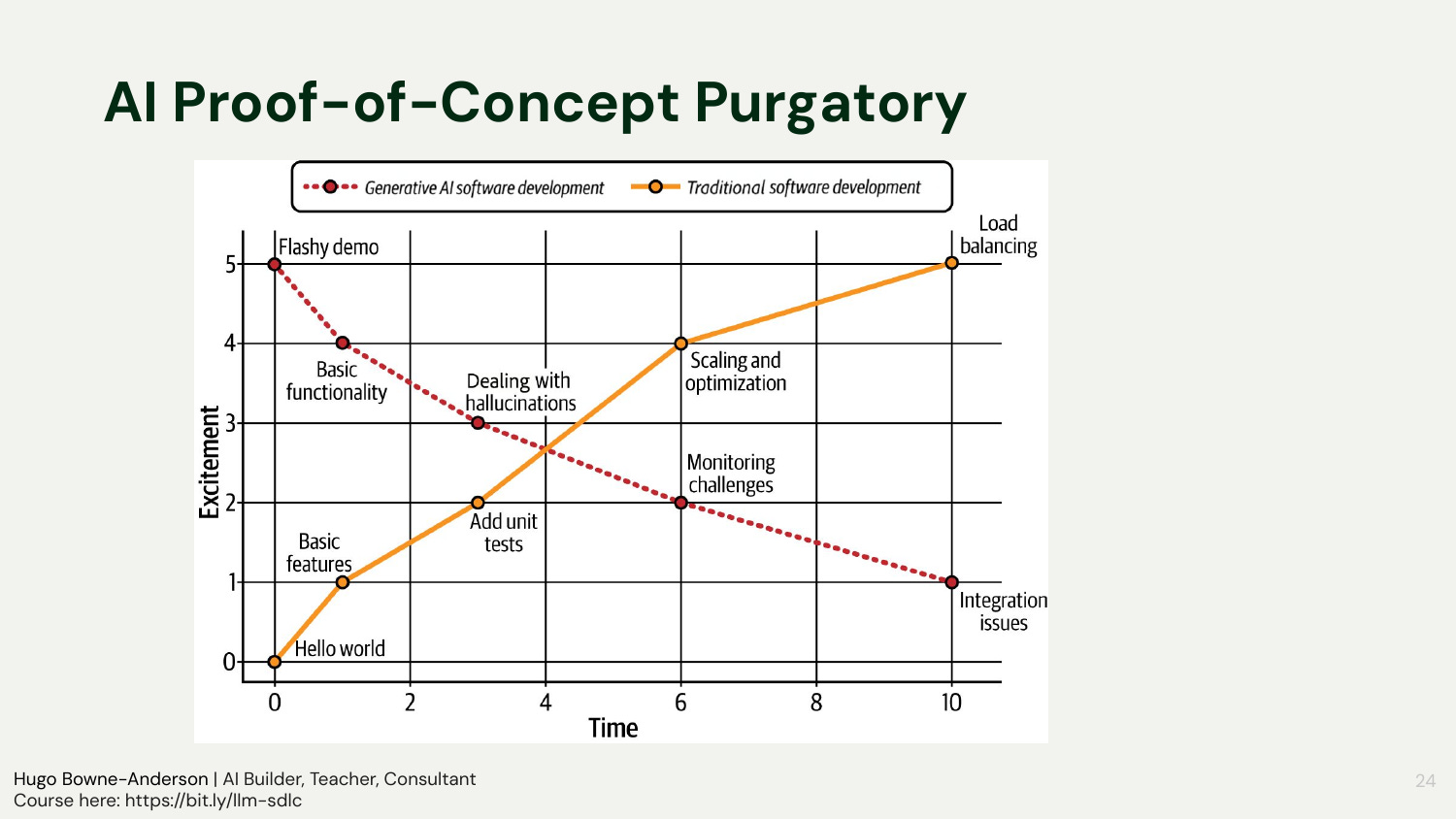
Flashy demos decay: initial excitement fades as fragility, hallucinations, and integration pain appear
Core diagnosis: teams lack goals, observability, testability, and a plan to evaluate over time
Desired curve: sustain or increase excitement through evaluation, logging, and iterative improvement
The session contrasted traditional software’s steady “excitement over time” with AI’s inverted curve: demos wow early, then problems compound. To reverse the trend, start with a clear user problem and measurable goals, treat evaluation as the center of gravity, and log everything to enable iteration. The aim is not to preserve the prototype as-is, but to refine or replace parts to achieve business outcomes.
“You see excitement decrease as a function of time, and this is what we refer to as proof-of-concept purgatory.”
[00:29:53]
Evaluation-Driven Development and AI/LLM SDLC

Continuous loop: build, deploy to limited users, observe behavior, evaluate, improve
Levers: prompt engineering, fine-tuning, RAG design, chunking, embeddings, tool definitions
Metrics: tie micro evaluations to macro business outcomes; separate retrieval and generation quality
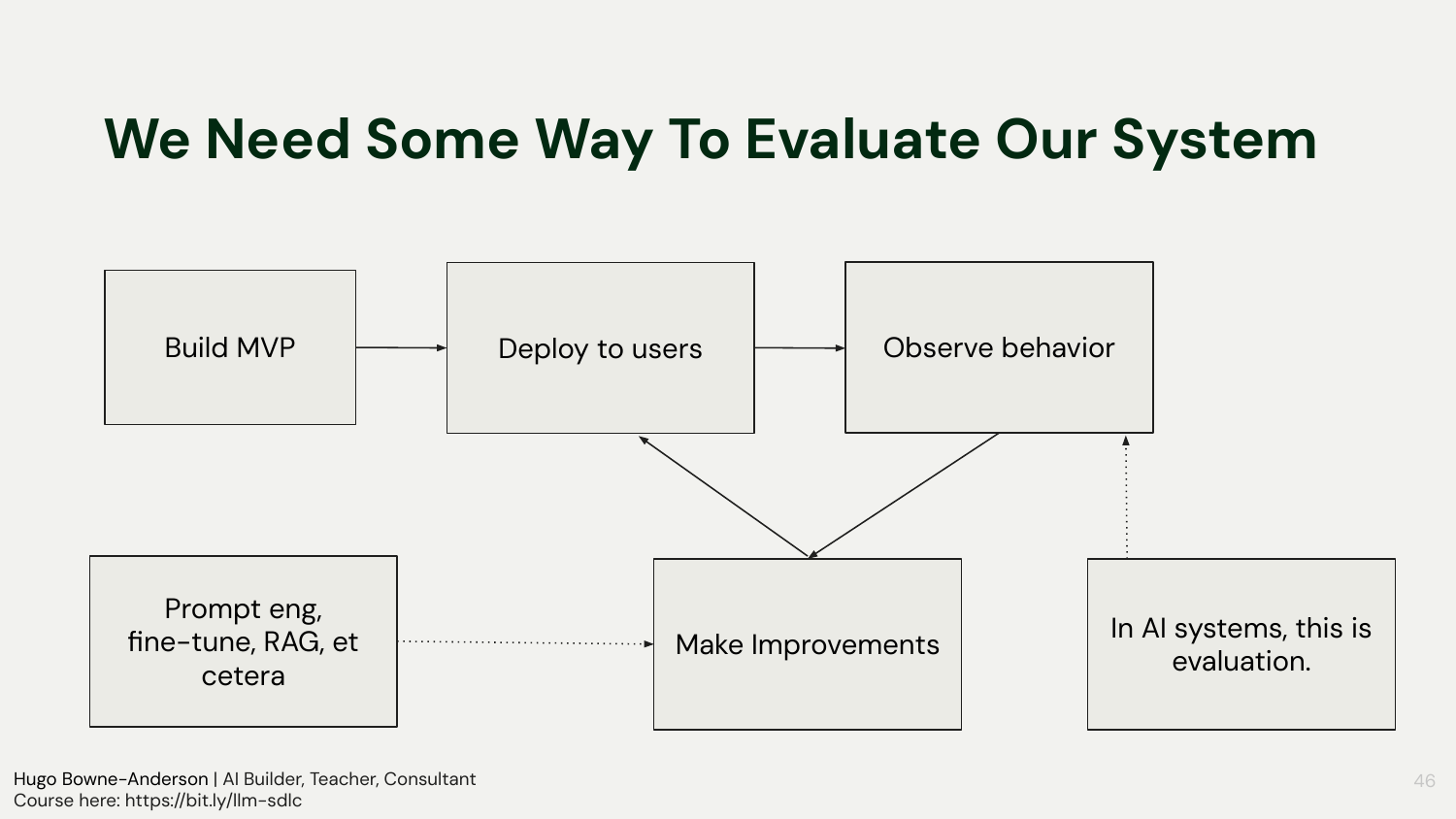
Evaluation is the core driver of LLM product development. Teams should instrument inputs and outputs, log richly, and use both domain expertise and binary pass/fail triage to identify improvements. Differentiate retrieval accuracy from generative quality in RAG pipelines, and choose levers accordingly, often starting with upstream data preparation. An AI-specific SDLC emphasizes rapid iteration cycles and staged deployments, plus robust logging, monitoring, and tracing to make changes safely amid non-determinism.
“We build an MVP, We deploy to users, we observe behaviour, make improvements.”
Retrieval-Augmented Generation and Early Framework Pitfalls
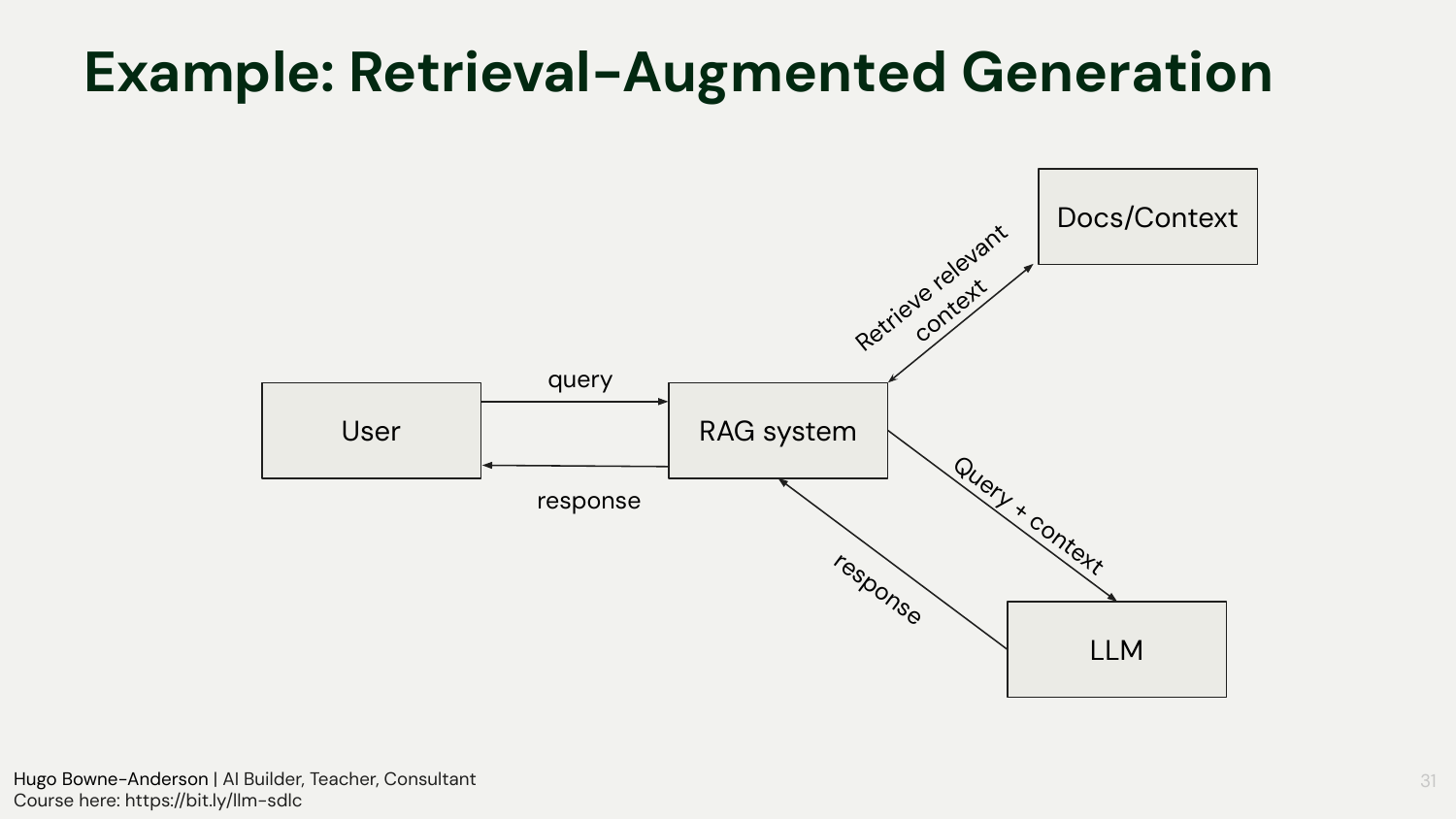
RAG in plain terms: give the model the right context so it answers from sources, not guesses
Premature abstraction: five-line quickstarts hide prompts, defaults, and embeddings, blocking iteration
Observability gaps: if you can’t see the exact prompt and inputs, you can’t debug or improve
RAG was defined through concrete questions like “What’s your refund policy?” and “How does our data loader work?”—use retrieval to ground the answer in your docs or code. The warning: early framework use often obscures which model, embeddings, and prompts are used, making debugging impossible. This is why “show me the prompt” became a rallying cry: if you don’t know what hit the API, you can’t evaluate or improve it.
“I can’t even see what the actual prompt that was sent to the LLM with Llama Index.”
[00:38:19]
Evaluating AI System Performance

Evaluation is the loop: build, deploy, observe, improve; repeat rapidly
Binary judgments at start: mark good vs bad before fine-grained scales
Micro to macro: from single-call correctness to impact on user and business outcomes
Evaluation was framed as the “observe” step in the AI SDLC, but with qualitative differences from traditional software: non-determinism and user variability demand tight feedback loops. Start simple: look at input-output pairs and score them as good or bad. Then expand toward macro metrics tied to the product’s goals (e.g., downstream conversion or time saved), not just the correctness of intermediate outputs.
“Then we observe the behavior, and then we make improvements, and then we deploy again, and so on.”
[00:40:01]
First Principles for AI Software Development

Inputs and outputs: the LLM consumes tokens via prompts and context, and emits text or structured outputs
Non-determinism (double entropy): variability in both user input and model output
From day zero: logging, monitoring, and tracing to capture prompts, contexts, outputs, and intermediates
The core of building with LLMs is simple to state: send tokens (system/user prompts, retrieved context, prior tool outputs), receive tokens back, and wire the result downstream. Everything else is about making this loop observable and controllable in the face of non-determinism. Treat evaluation as a first-order concern from the first prototype, and gather domain-expert feedback to ground judgments and guide iteration.
“LLMs are non-deterministic. Same inputs, different outputs…and very often not even the same inputs!”
[00:46:28]
The AI Software Development Lifecycle
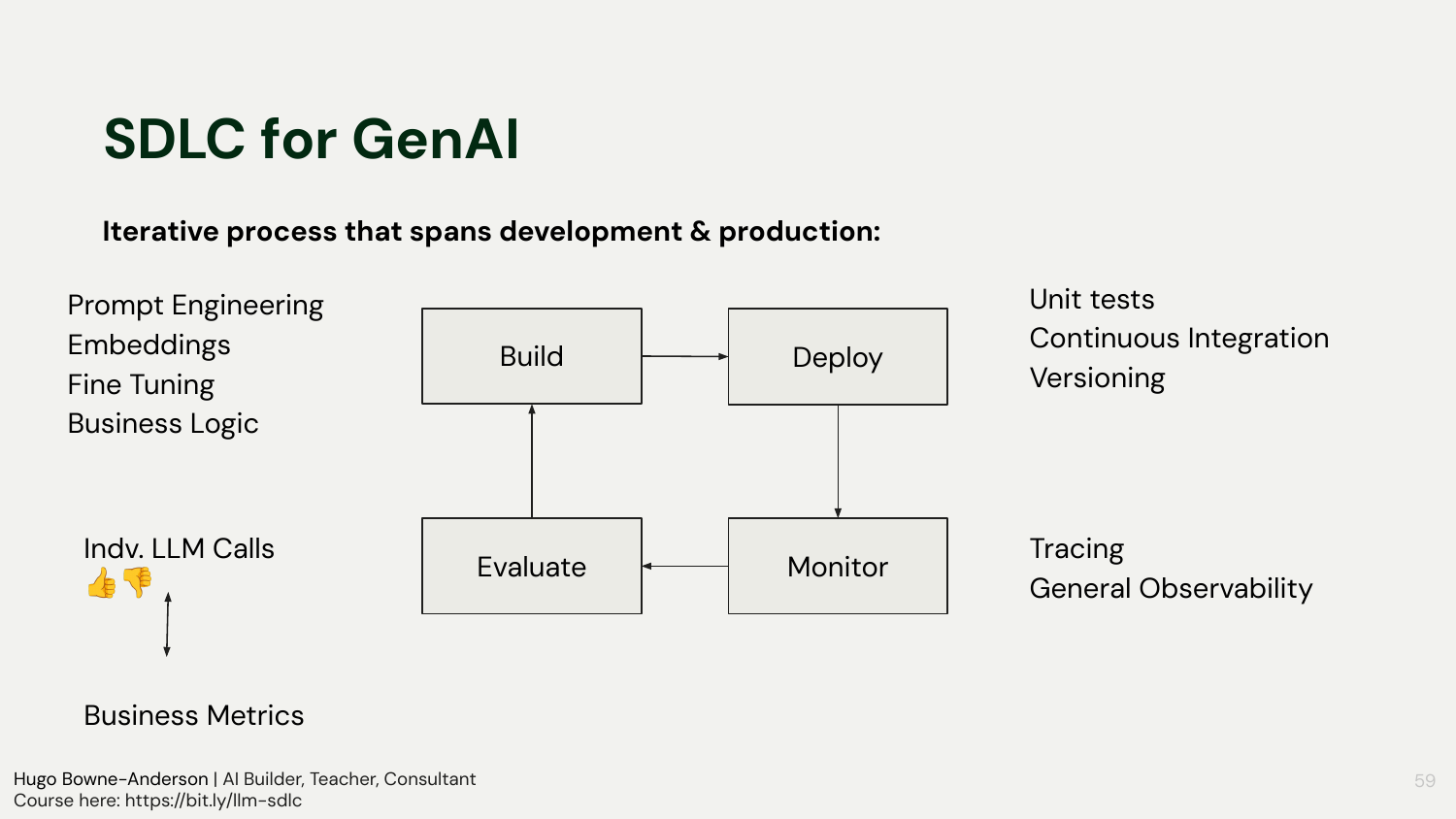
Iterative core: spec → build MVP → deploy → monitor → evaluate → iterate rapidly
Interventions: prompt design, retrieval, tool use, fine-tuning (less frequent), and business-logic changes
Guardrails and tests: unit tests, smoke tests, CI, versioning, and production observability
The lifecycle expands traditional SDLC with a faster and more evaluation-centric loop. Non-determinism and context drift mean you must expect ongoing change: prompts evolve, retrieval improves, tools get added, and business rules adjust. Effective teams operationalize testing and tracing early, wire evaluation into their release cadence, and make iteration cheap so that improvements stick.
“we spec it out, we build an MVP, we deploy, we monitor, we evaluate quickly, and we have rapid, very rapid iterations here.”
[00:52:22]
Q&A: Round 1
When (Not) to Use LLMs
The opening question: a student shared that every LLM workflow they built ended up simplified until traditional automation was the better solution. The LLM was “the bug, not the feature”
Discussion points included:
Code checks before LLM judges: if you’re testing structured output or checking whether the response contains a known string, use a regex or equality check. Basic classification often works better with smaller, cheaper, lower-latency models
Cost is shifting: Gemini is now cheap enough that high-throughput document classification “almost isn’t worth it to not use.” But LLM API pricing may not stay cheap, and the unit economics of most providers remain unclear
Regulated spaces: some domains require interpretability. LLMs are not interpretable models
Trust and complacency: a student building automated telemedicine visit notes had data showing reduced clinician time, but “people get complacent, start to trust the LLM too much, and don’t review as much as they should”
When human-in-the-loop backfires: if the output still needs human verification, you may have moved the cognitive burden, not reduced it. When does the review step become a liability instead of a safeguard?
A practical heuristic: LLMs handle the long tail of variable, unstructured inputs that would be painful to cover with rules. If your input has known structure, write code
The question of when not to use LLMs came up in the live session and kept going in Discord. The meta-question is always: what does it cost, what’s the latency, and can you evaluate what works best? Other considerations: application complexity, environmental and dollar cost, audit trails. As one student put it, reaching robust AI applications “will likely take years not days or months.”
“There are a lot of tasks that can be done more easily by just writing a couple of lines of code”[00:59:35]
👉 Join our final cohort of Building AI Applications for Data Scientists and Software Engineers. All sessions are recorded so don’t worry about having missed any. Here is a 25% discount code for readers. 👈
Section 2: Let’s Code and Build Together!
Hands-on: Codespaces Environment and API Keys
Prebuilt environment: Codespaces with dependencies (e.g., transformers/PyTorch) ready to run
Ephemeral spaces: fork/pull or download to persist work
API keys: Google (required), OpenAI, Anthropic; environment variables via .env
Participants launched a Codespace, activated the course environment, and synchronized the repo. Because Codespaces are ephemeral, saving work to a fork or downloading is essential. The group copied a .env example, populated keys (at least Google Gemini), and sourced the environment variables to prepare for running the apps that follow.
CLI RAG-Style Query App with LlamaIndex
Default opacity: the quickstart runs but hides model/provider and embedding defaults
Provider differences: Gemini, Claude, and OpenAI vary in tone and behavior (e.g., disclaimers)
Embedding dependency: even with Claude, LlamaIndex may use OpenAI embeddings by default
Running the notorious five-line demo showed retrieval working against a LinkedIn PDF and highlighted how little visibility exists into prompts and defaults out of the box. Switching providers produced noticeably different responses and safety behaviors. One surprising dependency surfaced: using LlamaIndex with Claude still required an OpenAI key because Anthropic doesn’t offer embeddings, and LlamaIndex defaulted to OpenAI embeddings.
“use Llama Index with Claude, you need an OpenAI key.”[01:19:40]
From Discord: A student from a previous cohort shared a Docker + MITM Proxy setup that intercepts every HTTP request LlamaIndex makes, revealing the default model, system prompt, and hidden behavior. Another noted that Gemini’s health-related disclaimers are “actually really hard” to suppress, making it a real evaluation case for their current work project. — tuttinator, wdhorton
Hands-on: Gradio UI, Logging to SQLite, and Tracing with Datasette
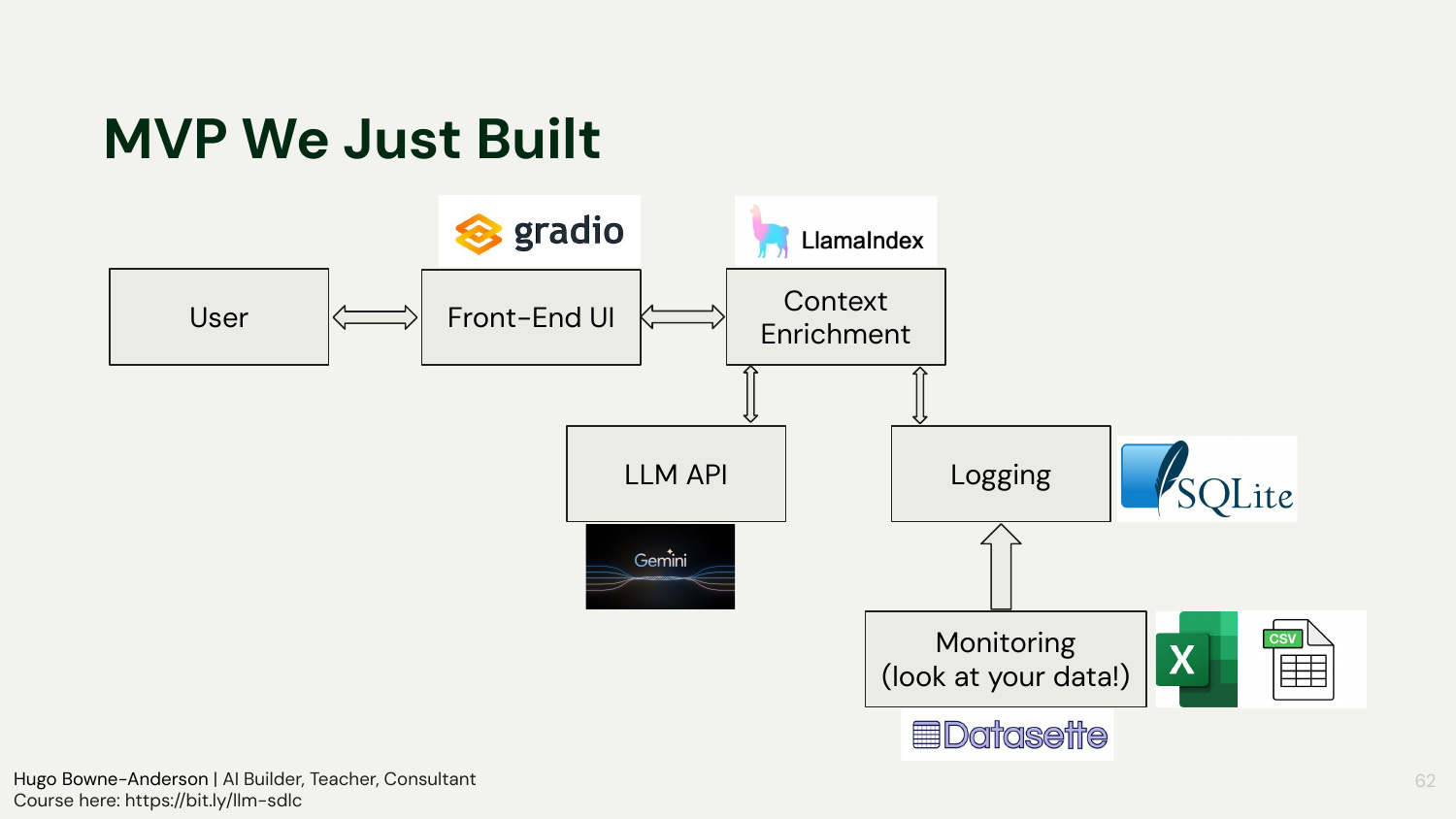
Fast UI for demos: Gradio made a usable front-end to upload a PDF and query
Start logging immediately: capture inputs, contexts, and outputs from the first prototype
Explore traces: use Simon Willison’s Datasette to browse, filter, and export evaluations
A lightweight Gradio front-end replaced the CLI and made interaction easier for testing. The app then wrote every query and response to a local SQLite database to make evaluation concrete. Datasette provided a zero-friction way to visualize traces, inspect specific input/output pairs, and export to CSV/JSON for manual scoring or future automated evals.
“How do you improve your app if you can’t evaluate it? How do you evaluate it if you don’t have anything to look at?”
[01:24:06]
Homework Briefing
Bypass frameworks: hit a model API directly from your app
Construct the full prompt: include the PDF text and your user query
Log everything: persist the exact prompt and the model response for later evaluation
The assignment focuses on foundational control and observability. Replace the framework call with a direct API request so you own the prompt and can see exactly what the model sees. Keep it simple at first: no chunking, embeddings, or retrieval—just pass the whole text. Persist prompts and responses to your logging store so you can evaluate and iterate next session.
“build a version of your Gradio app that just sends the prompt directly to the LLM API without using Framework, okay?”
[01:30:07]
Guest Talk: Building AI Applications with Modal
Modal Platform Overview
Developer-first serverless: think in terms of functions and code, not container plumbing
Two execution modes: serverless functions for stateless scaling, sandboxes for long-running or stateful work
Images and hardware: define dependencies once, assign GPUs when needed, scale with load
The overview reframed deployment as a developer experience problem: abstract away cloud boilerplate, IAM, and manual autoscaling so teams can focus on Python code. Functions scale up and down with traffic; sandboxes give you a persistent container lifetime for tasks like agents or orchestration. Images encapsulate dependencies, secrets flow from the platform, and the same API exposes web endpoints for clients.
“at its core, Modal is a… distributed compute platform with an eye on developer experience”
[01:37:20]
Walk-through: Modal App Wrapper and ASGI Serving
Define once, run anywhere: import modal, set an image, build an app, attach functions
Concurrency controls: cap per-container concurrency and autoscale per traffic shape
ASGI integration: wrap FastAPI or Gradio in an ASGI app and expose a URL
The wrapper mirrored earlier code patterns: start from a base image, pip-install your stack (LlamaIndex, PDF parsing, Gradio, SDKs), and include local files that need to run remotely. Concurrency settings determine how many requests a single container can serve before autoscaling. Exposing an ASGI app via the decorator pattern yields a standard web endpoint that scales across routes as function calls.
“And what this says is that this function that we’re decorating is going to return some ASGI app object”
[01:46:14]
Guest Q&A: Examples, Hosting LLMs, and Credits
Examples library: many end-to-end patterns for LLM serving, voice agents, and VLLM hosting
OpenAI API compatibility: host open models behind an OpenAI-compatible interface to swap providers
Credits: $500 per student, redeem by the posted deadline; valid for a year after redemption
The discussion pointed to public repos for deploying vLLM-backed models, voice agents, and agentic applications. Teams can often drop-in replace OpenAI clients by pointing them to a self-hosted base URL for OpenAI-compatible servers like vLLM or SGLang. Credit codes will fund substantial experimentation unless students intentionally run very large models.
Q&A Round 2
Speech-to-Speech Pipelines with NVIDIA NIM
Cascade voice agents: speech-to-text → LLM → text-to-speech as independent, scalable services
**NIM containers:** simple deployment by running NVIDIA registry images for ASR, LLM, and TTS
Orchestration pattern: frameworks like Pipecat route audio/text between service URLs
The voice agent pattern was presented as three separate GPU-backed services, each scaling independently and addressed by URL. Deployments leveraged NIM containers for rapid bring-up of ASR, a compact LLM, and TTS; the front-end established WebRTC while a lightweight bot orchestrated the pipeline. This separation of concerns makes it straightforward to swap components and scale bottlenecks independently.
“we just have this very simple, you know, cascade model voice bot, meaning speech-to-text, LLM, text-to-speech.”
[02:05:01]
Community Discussion Highlights
The Discord channel surfaced several threads worth preserving alongside the workshop content.
Agent ergonomics and the shifting role of code. Wes McKinney (creator of pandas) argued that as agents write more code, developer experience shifts from human ergonomics to agent ergonomics, and languages like Go may win for certain software types. A student extended this: tools like OpenClaw succeeded by wrapping CLIs with tool use, and wondered whether agent paradigms will try to apply software metaphors to non-software knowledge work. They’re already seeing results using patch and diff patterns with LLMs for transcript editing.
Non-determinism has a precedent. One student drew a parallel to concurrency programming as the closest existing analogue to non-deterministic LLM behavior: “it is very time dependent and one needs to plan around latency and the non-deterministic aspects of time.”
Sycophancy research. Two papers were shared on model sycophancy: OpenAI’s findings on GPT-4o and Anthropic’s research on understanding sycophancy in language models.
Further Resources & Next Steps
Tools mentioned during workshop
LlamaIndex for quickstart retrieval demos
Gradio for lightweight UI prototyping
SQLite and Datasette (Simon Willison) for logging and trace exploration
Modal for deployment: functions, sandboxes, images, concurrency, secrets
vLLM/SGLang for hosting open-weight LLMs with OpenAI-compatible APIs
Links shared by instructors
Homework assigned
Replace the framework call with a direct API request to a model provider
Manually construct the full prompt (PDF text + user query)
Log the full prompt and response; start with no chunking or embeddings
Related workshops or follow-up sessions
Builders Club later this week (support for Modal deployment and app debugging)
Next workshops: direct use of LLM APIs, prompt design, evaluation harnesses, guardrails/CI
Upcoming guest workshops: annotation for evaluation (with Prodigy), agentic search, and more
👉 Join our final cohort of Building AI Applications for Data Scientists and Software Engineers. All sessions are recorded so don’t worry about having missed any. Here is a 25% discount code for readers. 👈
The eval-driven approach is something I learned the hard way. Built an agent system that looked great in demos. Ran it overnight, and it accumulated subtle errors that compounded. Added structured self-evaluation after each task and the reliability changed immediately.
The part teams skip: evaluating the evaluation. Your eval criteria drift over time as the system changes. Someone has to maintain the evals, not just write them once. That maintenance cost is why teams eventually drop formal evaluation and go back to vibes.