
The Agentic Data Science Research Lab
How AI Agents Can Unlock the Original Promise of Data Science: Making Better Decisions, Not Coding Faster

Thomas Wiecki, co-creator of PyMC and lead at PyMC Labs, joined the Vanishing Gradients podcast from San Francisco to talk about agentic data science, decision intelligence, and how Bayesian and causal methods keep agents honest.
I recently caught up with Thomas Wiecki, who co-created the probabilistic programming library PyMC, earned his Ph.D. in computational psychiatry from Brown University, ran data science at Quantopian, and now leads PyMC Labs, where he applies generative AI and causal inference to actual business decisions.
We discussed how, 15 years after the Harvard Business Review crowned data science the “sexiest job of the 21st century,” the discipline still falls short of its original promise, outside a handful of large tech companies and financial firms.
We talked about how agents are starting to change that and deliver on the promise of data science by automating the procedural parts of a causal workflow and letting humans explore multiple analytical avenues in parallel, without taking the shortcuts we usually rely on under time pressure.
We decided to write a post for those who do not have 65 minutes to listen to the entire podcast. It captures some of our favourite parts of the conversation, including:
Why software caught the agent wave while data science got skipped
The trap of vibe science and why rigorous verification is the whole game
Navigating judgment, intelligence, and procedure to figure out exactly where humans need to stay in the loop
How to build an agentic research lab where you act as the principal investigator
What happens when 29 teams look at one dataset and get 29 different answers
The four layers of an agentic data science stack
Why the future of the field is about doing rigorous science rather than basic data analysis
How to start small, systematically build skills, and eventually scale up to decisions
You can check out the full episode on YouTube, Spotify, or Apple Podcasts. You can interact with the transcript directly in this NotebookLM transcript.
👉Want to learn how to apply agentic engineering to the world of data science? Come build the future of Agentic Data Science with us in our course starting this week!. It’s a live cohort with hands on exercises, capstones, and reusable agent skills, OSS code, and notebooks that will 10x your data science projects. Sign up here and use the code ADSVG10 for 10% off. Hit reply to enquire about group discounts👈
Jump to:
Software got the agent wave. Data science got skipped.
Software engineers are currently riding a wave of new agentic tools, rapidly building prototypes and refactoring entire codebases with a chat interface. We discussed how data science has largely missed this shift. The path forward for data teams looks nothing like the one software took. We reflected on how, 15 years after the Harvard Business Review crowned data science the sexiest job of the 21st century, the original promise of data science never really landed outside a handful of large tech companies and quant shops. Instead of driving better, informed decisions, most data teams are stuck acting as ticket-takers building dashboards.
Only 15 years ago, we were promised that data science was going to be this thing and create all this value for people, and I think nowadays it’s mostly viewed as a cost center in most companies – something that you ask a question and then it takes 3 months and then you get some cryptic answer back.
— Thomas Wiecki, 00:04:15
Despite this stagnation, Thomas argues that we are at a historical moment where three distinct trends are finally converging:
Decision science, a field with strong theoretical foundations that historically struggled to make it into practice
Bayesian and causal frameworks, which are rigorously correct but notoriously punishing to use, even for experts
The most recent piece of the puzzle is the rise of agentic interfaces that can finally make these advanced methodologies accessible to non-technical users
Before, at PyMC Labs, we spent a lot of our time just building these models. But getting new answers from them required an expert data scientist and a lot of time. Now, through agentic interfaces, [we can] really get usable decision science.
— Thomas Wiecki, 00:06:22
When we think about bringing agents into data workflows, the obvious translation from software engineering is generating code. But Thomas points out that the real value of a data science agent is not simply asking a large language model (LLM) to write pandas code.
The true value is the ability to do causal and probabilistic analysis properly for the first time. Human data scientists are naturally constrained by time and take necessary shortcuts, skipping rigorous checks or failing to explore every analytical avenue. Agents can be instructed to be strictly programmatic, running parallel analyses and exploring all pitfalls without the usual fatigue.
In a word, data science requires a completely different agent stack, moving teams away from simple descriptive stats and closer to the actual decision function.
The vibe science trap: Verification is the whole game
We need to stop thinking about prompting and start designing complex agent-based data science systems. The only way out is a rigorous verification layer.
A common failure mode when working with LLMs is that, because LLMs sound so plausible, pointing them at messy inputs often obscures underlying problems. During the recording, a listener named Pasquale dropped an observation in our Discord about how AI with bad data fails at data science, arguing that it has created a wave of vibe data scientists who cannot verify what the models say.
I shared my own heuristic on this: no data is often better than bad data. An LLM will not automatically surface the poor signal-to-noise ratio in your dataset. Instead, it will paper over the mess with prose that sounds completely authoritative but means nothing.
It’s tempting to think of AI agents as tireless oracles that will grind through these data issues for you, but they take just as many shortcuts as we do. We discussed how these interactions prove that agents need the kind of verification scaffolding you would provide to a junior analyst.
Everything I’m saying [relies on having] the tooling in place. It’s not that you just give the data to Claude Code and let it run wild. That will usually produce vibe science.
— Thomas Wiecki, 00:14:10
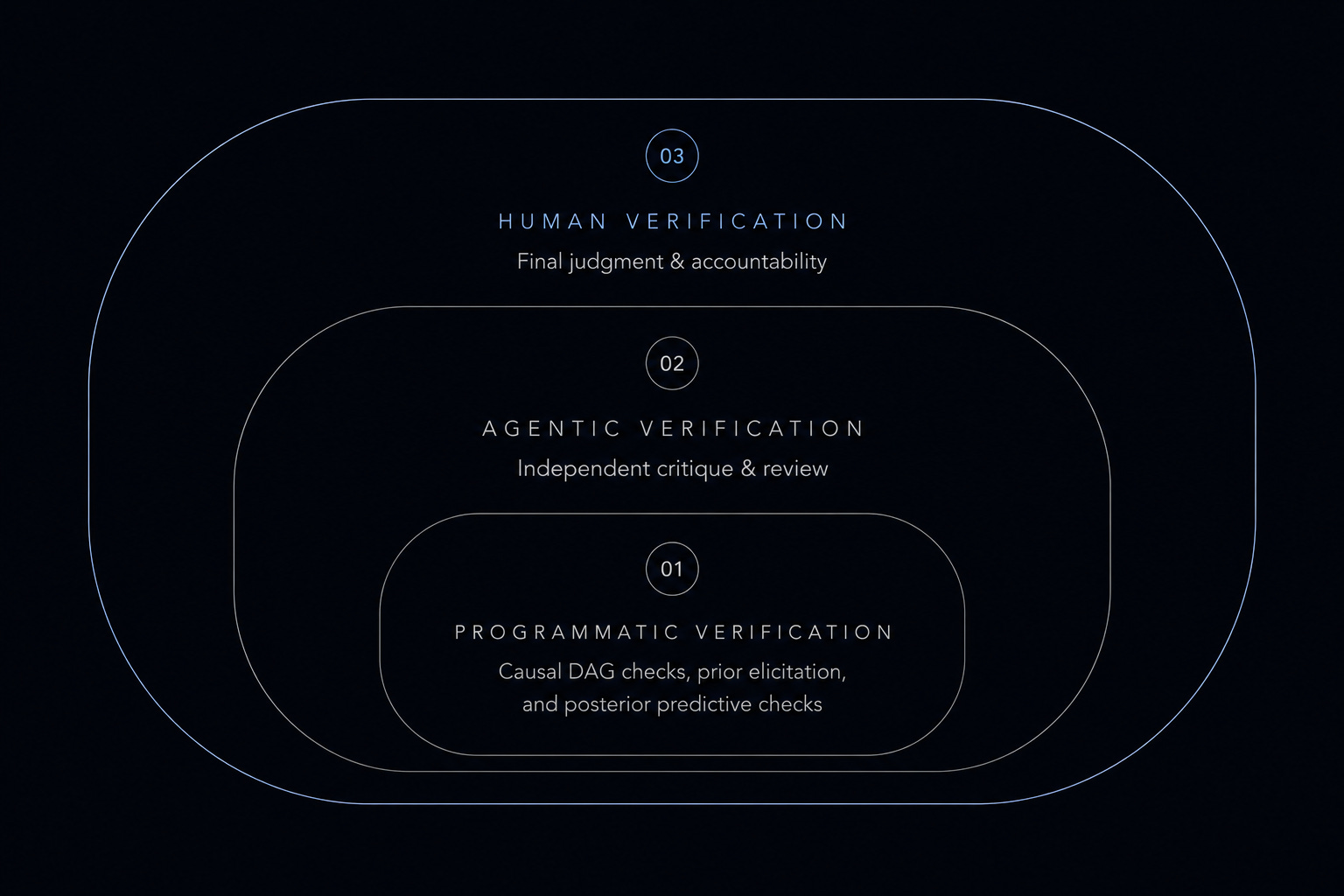
To escape this trap of vibe science, Thomas argued that we need to stop thinking about prompting and start designing complex agent-based data science systems. The only way out is a rigorous verification layer, which Thomas breaks down into three necessary components working together at the right moments:
Programmatic verification: Use hardcoded checks anchored in causal and Bayesian workflows. Before the agent builds a model, it defines the causal DAG and the confounders, then handles prior elicitation. If the model is poorly constructed, the PyMC sampler will fail and complain loudly; posterior predictive checks then verify the fit against reality.
Agentic verification: Establish a separate agent specifically tasked with reviewing and critiquing the primary agent’s analytical choices, acting as a checks-and-balances layer.
Human verification: Incorporate tight human-in-the-loop verification keeping the developer’s eyes on every step early on, before any of the above gets automated.
Thomas shared his workflow rule for moving from manual checks to automated systems: He starts with a tight human loop and packages each verified step into a skill over time.
Everything that I can verify, I can ultimately move into a skill... [For] things that I do repeatedly, I will just encode as a skill and then over time automate the workflows... to where I can slowly take my hands off the wheel and let the autopilot kick in.
— Thomas Wiecki, 00:18:00
This tightening loop is the exact path from vibes to a reliable system.
We wrapped up the section by comparing this to pandas creator Wes McKinney’s modern agentic workflow: Wes barely reads the code he ships now, but he is certainly not vibe coding. He has built rigorous verification pipelines. Reading code is not actually about reading at all but about verifying that the code works as intended. Once you build a robust verification layer, the trust comes entirely from the system’s checks and balances, not from human eyeballs scanning every line.
Where to stay in the loop: Procedure, intelligence, judgment tasks
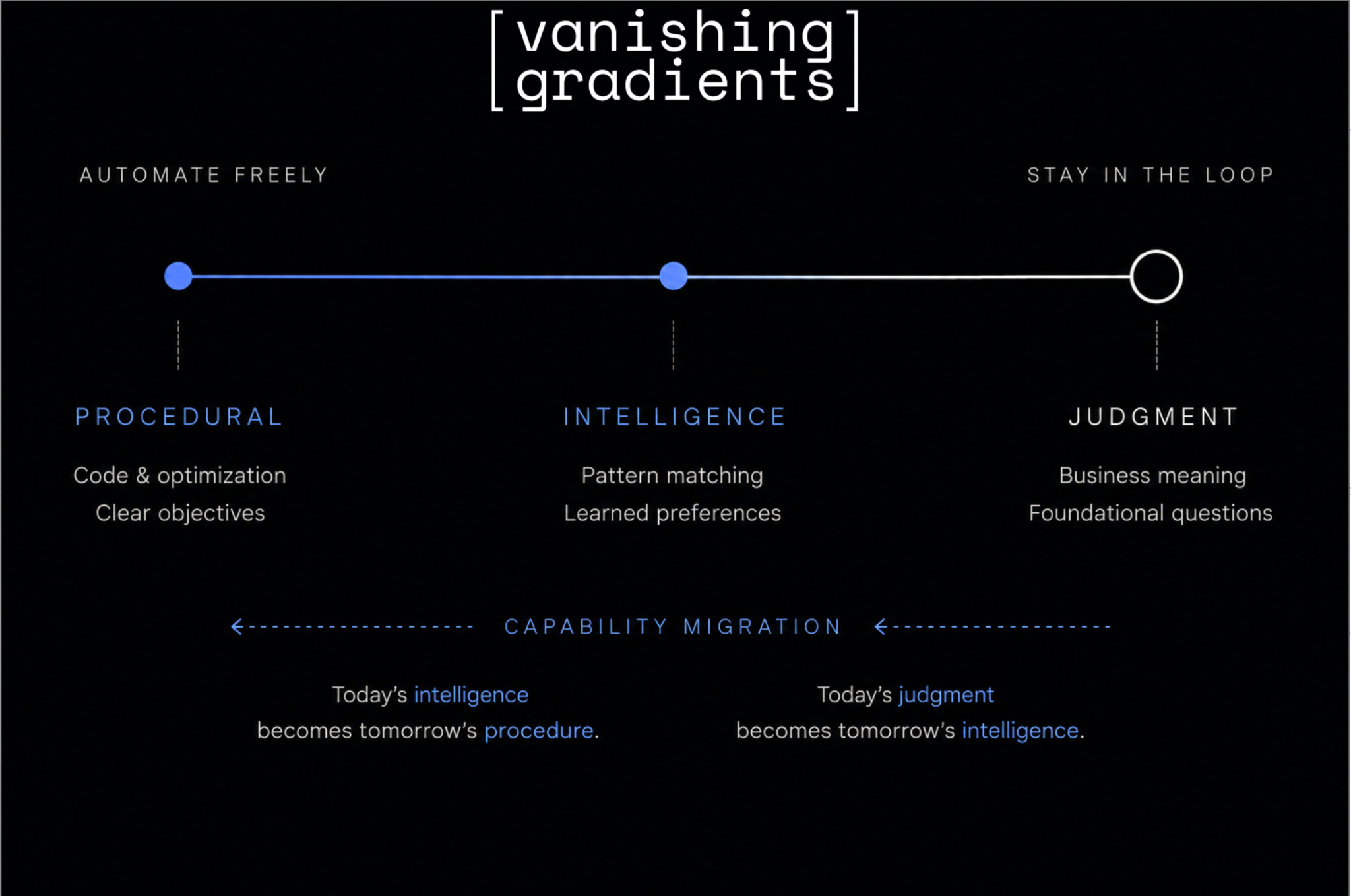
How do you decide what to hand off to agents?! Not every task has the same shape, which means the agent should be trusted accordingly. I shared a framework for categorizing work into three buckets, each with a different recommended level of automation:
Procedural tasks: Write standard pandas or polars code, run hyperparameter sweeps, or perform hill climbing when the mathematical objective is clear. Automate freely: These tasks have easily verifiable success criteria and do not require constant supervision. Engineers ship millions of lines of code without reading every line by relying on rigorous verification pipelines.
Intelligence tasks: Pattern matching, reasoning, and what looks like mimicked judgment. For example, intelligence is the way an agent’s auto-accept mode learns a developer’s preferences and moves from requiring approval for every edit to automatically accepting the safe ones. Automate with verification: Encode judgment into intelligence over time as a user packages verified actions into reproducible skills.
Judgment tasks: Answer the foundational questions: What business question are we actually answering? Does this decision make sense in the real world? Thomas argues that the most meaningful business questions are follow-up questions, such as asking whether to increase TV ad spend based on specific data constraints. Stay in the loop here to ensure the problem is properly understood before any automated machinery or workflows come online.
And then at the end, where it’s really about interpreting the outputs and the suggested decision, we want to be very interactive and have great agentic tools for the human to [be able to] inquire into the model and the answers to make sure that they make sense.
— Thomas Wiecki, 00:21:49
I hand off tasks like model selection or hyperparameter tuning because the objectives are clear. I prefer to remain in the loop for exploratory data analysis (EDA). When an agent processes a dataset and outputs a complete EDA report all at once, the result is a wall of high-density information. These exploratory phases naturally surface new questions that require active human thinking, making them a natural place to maintain a conversational, step-by-step verification process.
In the agentic research lab, you’re the PI
Thomas views the future of data science through a specific pattern that he keeps coming back to: treating the data team like a research lab. In this model:
The human acts as the principal investigator (PI), setting the overarching research question and guiding the strategy.
The AI agents operate like capable graduate students, farming out the analytical paths and doing the heavy technical work.
The human then integrates the findings and makes the final decision. This approach solves a common problem we discussed early in the segment: simply asking an LLM to analyze marketing data often produces superficial or meaningless answers if it lacks a rigorous causal framework.
Thomas explained how this new workflow begins directly where stakeholders already operate, right inside the team chat. PyMC Labs built an internal agent called Daemon (powered by the Claude Code Agent SDK) that listens in their standard communication channels. When a stakeholder asks a routine question, like whether they should rebalance their marketing budget for the new quarter, Daemon picks it up. The agent already possesses access to the underlying data, understands the company schemas, and holds the right tools to begin exploring. By bringing this process into a shared environment, the organization transforms AI from a siloed desktop application into a shared workspace.
There’s just something really fundamental happening when you go from single player to multiplayer LLM use.
— Thomas Wiecki, 00:28:10
Integrating Daemon into a multiplayer LLM experience creates an organic educational effect across the company. Instead of junior team members struggling in isolation, the whole organization sees what their colleagues are doing in real time. A junior data scientist can watch a senior team member connect LinkedIn data, layer in HubSpot metrics, and combine it with Google search terms to produce a sophisticated analysis. They learn complex data manipulation patterns by watching how expert colleagues prompt and guide the agent through the task.
Behind this accessible chat interface sits a modeling engine called Decision Lab, an open source tool designed for full causal and Bayesian workflows. Thomas pointed out that rigorous analysis rarely follows a single route. Instead of picking just one way to clean the data or choosing a single model, Decision Lab explores multiple analytical paths in parallel.
What’s key is that it’s not just one path. It’s not ‘here is the way to clean the data, the one way to remove outliers, and the one type of model you can build.’ It’s actually a garden of forking paths: it goes through all these different choices in parallel and explores them in a tree-based structure. And at every step it has the verification layer...
— Thomas Wiecki, 00:30:52
Once the agent navigates this garden of forking paths, it consolidates the results into a final report. Daemon often spins up a Jupyter Notebook server to show exactly where the different models converge or diverge. This is where the PI model becomes necessary. If 10 different analytical approaches yield 10 different answers, the system highlights that uncertainty. The data scientist remains strictly in the loop at this stage to review the methodology, verify the outputs, and ensure the agent is returning correct results.
Finally, we explored what happens when the verified analysis goes back to the non-technical stakeholder. Rather than handing over a static report, PyMC Labs built Decision Lens, an agentic dashboard that Daemon can spin up on demand. Stakeholders can interact with the verified models directly through a chat interface. They can ask, “What if we move 10% of the budget to TV?” and the agent will instantly generate a new plot reflecting that hypothetical scenario. They can drag that visual directly onto their dashboard. This interaction model reshapes the day-to-day relationship between data scientists and stakeholders.
The four layers of an agentic data science stack

Really important, which we haven’t talked about a lot, is the domain expertise. That’s where skills come in... the agent can selectively get something from the database. So it’s not that they have to know all of this just from the pre-training. We can equip them, and those [skills] are curated and verified and tested for safety.
— Thomas Wiecki, 00:40:49
So what then do you actually need under the hood to make these systems work in production. Strip away the specific product names and shiny marketing and you are left with a consistent architectural pattern that other data teams can copy. We discussed how any robust setup ultimately requires four distinct layers:
Harness / runtime. The fundamental loop that gives an agent the ability to take actions, whether Claude Code Agent SDK, Codex, or another tool. My mental model: the LLM is Krang the Brain from Teenage Mutant Ninja Turtles, and the harness is the mechanical body that lets it actually do things in the real world. A harness is not something a lab ships to you fully formed. It is a dynamic piece of infrastructure you must continually evolve, because it determines the exact context the model receives.
Skills. Curated domain expertise loaded only when needed: a description-first approach where the model fetches full content on demand. This avoids context pollution while equipping the agent with knowledge that’s been curated, verified, and tested for safety. Thomas highlighted the Decision Hub built by Luca Fiaschi at PyMC Labs, a repository of specialized skills for building models, using scikit-learn, and generating compelling slide decks. A great public example is Randy Olson’s plotting skill, which applies Tuftean principles to data visualization.
Orchestration. Infrastructure for running multiple analysis paths in parallel: when one agent loop isn’t enough and you need ten branches at once. Thomas’s team uses Flyte for spinning up workflow servers to handle complex parallel runs seamlessly.
Observability and evaluation. Logging and analysis tools to inspect what the agent has been doing and inquire into its choices. This ensures reliability through visibility, testing, and continuous improvement.
What is actually the benefit of adding all these custom instructions, and then how do we optimize that through a capacity kind of loop. Those four are a pretty good stack of individual components that any good agentic data science system should have.
— Thomas Wiecki, 00:43:41
I also shared a quick aside about an 8-bit video skill that turns a guest photo into a retro animated clip. Cute demo, real point: skills are how you package highly specific, multi-step actions into a single tool the agent can call reliably.

Doing science, not data analysis
We spent a good portion of the episode unpacking the most foundational argument of our conversation. Combining AI agents with Bayesian and causal modeling is not just a stylistic preference for how to do math. It is the framework you need to force an agent to reason backward from what it observes to the actual process that produced the data, rather than generating very expensive nonsense.
LLMs are fundamentally trained to sound plausible, which means they are uniquely prone to hallucinating confident explanations for data. Without a structured framework that forces them to reason about how the data was actually generated, the promise of “agentic data science” easily collapses back into descriptive slop with extra steps. Thomas articulated exactly why this is such a persistent problem for builders today:
They produce answers, and this is one of my biggest pet peeves with them: they always produce answers, and it’s really good at sounding very confident and plausible. That’s what they’re trained on: just sounding plausible. And it’s really hard then to make sure that they’re actually telling you something correct.
— Thomas Wiecki, 00:51:15
This is why we discussed the necessity of probabilistic programming as a guardrail. Bayesian methods are inherently transparent, meaning you can inquire into the model at every single step of its execution to see exactly what the agent is doing. If an LLM tries to fake uncertainty or hallucinate a relationship that does not exist in the data, the math itself pushes back. As Thomas noted around, if an agent builds a poorly constructed model, the PyMC sampler will fail and complain loudly. This inbuilt programmatic validation keeps the system honest in a way that prompt engineering cannot.
Thomas shared a helpful mental model for how these statistical concepts fit together: the best Bayesian models are causal, and the best causal models are Bayesian. A probabilistic model without a causal structure cannot properly answer counterfactual questions, while a causal model without probability struggles to propagate uncertainty accurately. You need both to map out the real world.
To ground this, Thomas shared a specific example from his work with Colgate. Imagine a company launches a new kids toothpaste and total sales immediately go up. On a dashboard, it looks like a straightforward win. But without a causal understanding of the process, you cannot tell if you achieved real incremental growth by taking market share from a competitor, or if you simply cannibalized your own existing products and shuffled the chairs around. You tease that apart using discrete choice models, which explicitly map out the purchasing process:
Preference clusters: Customers walk into the store belonging to specific preference clusters, for example, parents shopping for kids toothpaste, adults shopping for whitening, and so on.
Assortment with attributes: Customers evaluate what’s on the shelf: products with prices, attributes, and stock levels.
Utility-maximizing choice: They choose the product that maximizes their individual utility, leading to the final purchase.
At the end of the day, you only observe that final purchase. But by using these frameworks, you can empower an agent to reason backward from the observation to the latent preferences that caused it. This marks the difference between reporting on a spreadsheet and doing actual science with data:
It’s not just data analysis, it’s data science. Really understanding what the latent processes are: the things that I can’t observe but that have the causal effect on the outputs that I’m observing. Then I want to reason backward from the thing that I observe to the thing that actually upstream caused these effects, and then in a causal model, of course, ask ‘what-if’ questions.
— Thomas Wiecki, 00:53:51
Start small, build skills, and scale up to decisions.
We wrapped up the episode by exploring the logical next steps for the professional data scientist who is already using AI agents to write pandas code. Thomas recommends starting with a single, repeated analysis, such as a weekly summary or a quarterly report, and encoding that specific workflow into an automated skill. The goal is to run this skill repeatedly, watch it break in real-world conditions, and fix it.
By getting deep on one specific stack before attempting to generalize, you build a practical understanding of system reliability. Thomas notes that you cannot reason about observability or evaluations in the abstract. You have to experience the friction directly to understand what an end-to-end analysis run actually produces and where it falters.
You really get deep in it, you understand it, you understand what the pitfalls are, what the individual components are... where does it work, where does it fail, and what do I do when it fails?
— Thomas Wiecki, 00:58:52
Once a developer understands these failure modes, Thomas suggests they are in a strong position to climb the analytics ladder. We discussed how most data teams stop at descriptive analytics, simply summarizing what happened. The real value unlocks when you move into decision-theoretical frameworks and causal machinery. The focus shifts from asking what the data looks like to determining exactly what business action the analysis supports.
Key Takeaways
Run your data team as an agentic research lab: You act as the Principal Investigator, agents farm out analytical paths in parallel like grad students, and you integrate the findings. This solves the problem that no human is realistically going to manually run 50 different ways of analyzing the same dataset.
Verification is the whole game: Build three layers working together (human, agentic, programmatic), each at the right moment. An LLM pointed at messy data won’t surface problems. It will paper over them with prose that sounds completely authoritative and means nothing.
Let agents bring Bayesian and causal methods within reach: You do not need to be a Bayesian expert to benefit. Agentic interfaces can walk you through the workflow step by step (priors, causal structure, posterior predictive checks), and the math itself pushes back when something is wrong. This is what separates real decision support, like Colgate-style incrementality vs. cannibalization, from descriptive slop with extra steps.
Start with one repeated analysis, then map your work to judgment / intelligence / procedure: Take a quarterly report or weekly summary, encode it as a reusable skill, watch it break in real conditions, and fix it. Then categorize your daily work into procedural, intelligence, and judgment tasks, and explicitly encode into your skills where you want the agent to pause and ask for human direction.
The integration of agentic workflows into data science shifts the practitioner’s role from writing procedural code to defining decision-theoretic frameworks. Building this intuition requires targeted experimentation and a clear map of where human judgment outpaces computational pattern matching. You can explore these methodologies in the Master Agentic Data Science course (use code ADSVG10 for 10% off).
LINKS
Open-Sourcing Decision Lab: Scaling AI Judgment in Data Science (PyMC Labs blog)
Agentic Data Science course with Hugo, Thomas, and Luca (10% off with code ADSVG10)
👉Want to learn how to apply agentic engineering to the world of data science? Come build the future of Agentic Data Science with us in our course starting this week!. It’s a live cohort with hands on exercises, capstones, and reusable agent skills, OSS code, and notebooks that will 10x your data science projects. Sign up here and use the code ADSVG10 for 10% off. Hit reply to enquire about group discounts👈