
Harness Engineering: Why Agent Context Isn't Enough
A conversation with Jeff Huber, CEO of Chroma, on agent harnesses, sub-agents, and why code unlocks emergent capabilities

In a recent conversation on the Vanishing Gradients podcast, I spoke with Jeff Huber, CEO and co-founder of Chroma, about the fundamental shifts happening in AI-powered search and AI system development. We talked about moving beyond simple retrieval and RAG, agentic search, the discipline of context engineering, and the practical challenges of building reliable AI systems and agent harnesses.
We decided to write a post for those who do not have 60 minutes to listen to the entire podcast. It captures some of our favourite parts of the conversation that can help builders today:
What changes for builders when we’re moving from human queries to agentic search,
Context engineering: the real job of building AI systems,
How to build “agent harnesses”: tools, sub-agents, and workflows,
Practical advice for building reliable systems today (start with hybrid search, create a golden dataset, cluster and analyze your data, engineer your tools thoughtfully),
The Outer Loop of AI Engineering: continuous improvement and evaluation.
👉 This was a guest Q&A from our November cohort of Building AI Applications for Data Scientists and Software Engineers. It’s a live cohort with hands on exercises and office hours. Our final cohort starts March 9. Here is a 25% discount code for readers. 👈
Jeff and his team at Chroma are also kindly sponsoring our final cohort with $250 in Chroma Cloud credits for all students. That’s part of $1,300 of credits everyone gets in state-of-the-art compute and AI tooling credits: we hope you come build with us!
You can check out the full episode here.
From Human Queries to Agentic Search
Firstly, we’re in the midst of a paradigm shift: moving from a world where humans manually search for information to one where AI agents do it for us.
Traditional search involves a human
authoring a query,
executing it, and
interpreting a limited set of results, like a page of blue links.
In agentic search, an AI agent can perform complex, multi-hop searches, synthesizing information from hundreds or thousands of sources to answer a single, complex question.
Our observation is that we’re really moving from a world where humans are authoring search queries and humans are executing those queries and humans are digesting the results to a world where AI is doing that for us. If you’ve used the deep research tools within ChatGPT, Claude,, etc., you’ll notice they don’t only look at one page of blue links. They’re actually canvasing hundreds of thousands if not more pages of internet to try to find an answer to your question.
— Jeff Huber, 00:00:00
This new model changes the nature of search itself. Instead of a single query-response loop, an agent might execute many queries in sequence, composing the results into a comprehensive answer. The challenge for builders is to transfer the intuition humans have developed for searching (knowing when to start, stop, or change strategies) into these automated systems (00:14:35).
Context Engineering: The Real Job of Building AI
“Context engineering does a few things. Number one, it is the job today. If you’re looking to build a production system, that is the job: engineer your context window. Prompt engineering’s like script kitty versus context engineering’s more like software engineering.”
– Jeff Huber, 00:20:00
As applications become more complex, “prompt engineering” is an insufficient term. Jeff argues that the more critical and accurate discipline is context engineering: the systematic process of curating the information an LLM receives.
Context engineering is necessary because simply filling a large context window is not a viable strategy for production systems. We spoke about several reasons:
Context Rot: LLM performance degrades as the context window size increases, especially for tasks requiring high attention or complex reasoning (00:09:54). A simple task like repeating a sequence of words shows a clear drop-off in accuracy as input length grows (00:32:52).
Cost and Latency: Processing millions of tokens is slow and expensive, making it impractical for user-facing applications (00:31:14).
Distraction: Irrelevant information in the context can easily distract an agent, causing it to make mistakes or repeat errors, even if it previously identified them as incorrect (00:18:43).
The goal of context engineering is to provide the agent with high-precision information while removing noise. It is the primary lever builders have to control an agent’s behavior and ensure reliability.
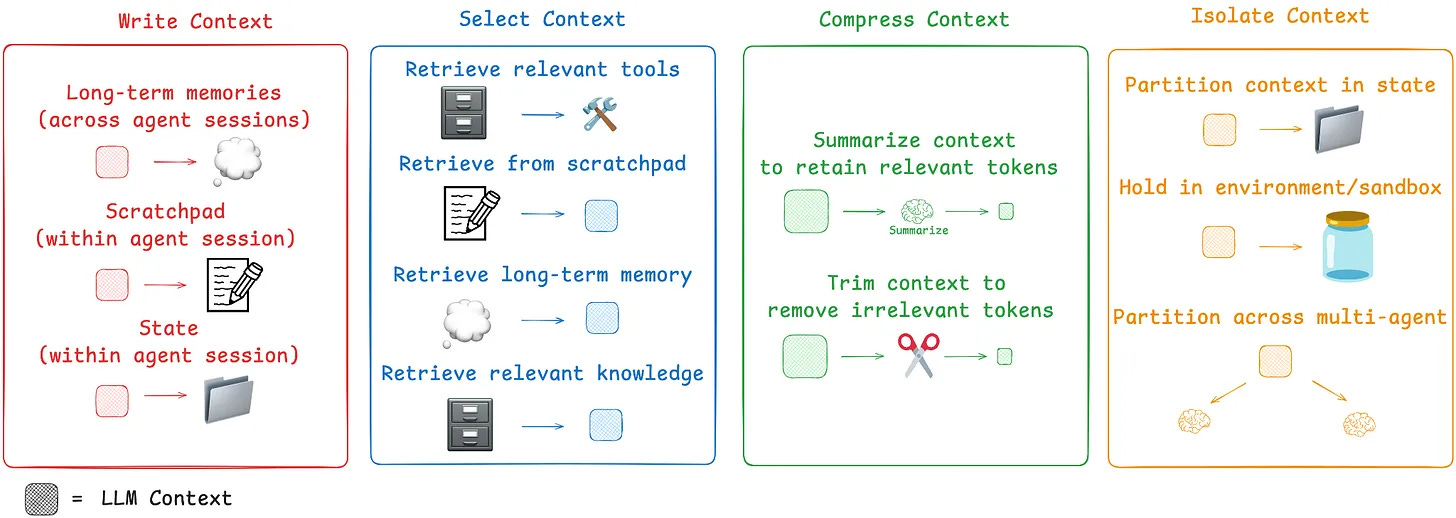
Building the “Agent Harness”: Tools, Sub-Agents, and Workflows
The capabilities of an LLM are defined not just by the model itself, but by the environment it operates in. This environment is the agent harness: this is the collection of tools and capabilities an agent can access.
The harness might include (00:24:42):
The ability to write and execute code.
Access to a file system for planning or as a scratchpad.
A suite of search tools with clear descriptions of when to use them.
The power to spawn specialized sub-agents to handle specific tasks.
Using sub-agents is an emerging best practice for managing complexity, context rot, and distraction. For example, a main orchestrator agent could delegate tasks to dedicated sub-agents for search, memory, or citation generation, as seen in some of Anthropic’s research systems (00:26:38). This modular approach keeps each agent’s context clean and focused.
When Jeff and I spoke, sub-agents weren’t yet universally agreed upon as best practice, but Jeff predicted that would change within six months. Why? Because different classes of inference workloads demand different types of inference, and once that becomes clear, sub-agents will be the obvious way to match the right approach to each task. And that’s what we’re seeing now!
Agent harnesses are becoming increasingly important, so much so that “What is an Agent Harness?” has been one of the top questions about AI Engineering from 300+ Engineers.
Jeff notes that people are starting to call this “harness engineering”: it’s not just about the context you give the model, it’s about the tools and environment it sits in. Give an agent the ability to write and run code, and new capabilities emerge:
Coding Agent are General Purpose Agents
We also talked about how giving an agent the ability to write code is particularly powerful. There had been discussion (including from Cloudflare) that this is because models are well-trained on code. Jeff argued that this isn’t the core reason. The real reason is that code acts as a scaffold that enables more creative composition of tools, unlocking emergent, multi-hop reasoning capabilities (00:25:53).
For instance: a user asks what happened on a Monday. The agent imports datetime to figure out which days were Mondays, then searches by date. That kind of reasoning emerges naturally when code is the scaffold.
This is also why coding agents are really general-purpose agents in disguise. Once you give an LLM the ability to write and execute code, it can do far more than you’d expect. As Armin Ronacher wrote about Pi (“the minimal agent that powers OpenClaw”):
If you want the agent to do something that it doesn’t do yet, you don’t go and download an extension or a skill or something like this. You ask the agent to extend itself. It celebrates the idea of code writing and running code.
This is also why tools like OpenClaw and Claude Cowork have taken off!
Watch this 2 minute video to see how a basic coding agent I built in 131 lines of Python can clean your desktop and why you should think of coding agents as “computer-using agents” that happen to be great at writing code:
If you’re interested in how powerful coding agents are, also check out my recent workshop Building Agents That Build Themselves with Ivan Leo (ex-Manus) where we build agents that can write their own tools and hot-reload them on the fly (via a factory pattern)!
Practical Advice for Building Reliable Agentic Retrieval Systems
We had a wonderful chat about practicalities for builders working on search, retrieval, and agentic systems. A few of the most important best practices for developers currently building agentic systems we discussed were:
Start with Hybrid Search: Combining lexical search (like BM25) with semantic vector search is a robust default strategy. Their strengths and weaknesses are complementary, often leading to better recall and precision out of the box (00:07:41).
Create a Golden Dataset: Evaluation is critical. Generate a “golden dataset” of queries and their expected correct outcomes to benchmark your system’s performance. LLMs can be used to help generate this initial dataset (00:36:46).
Cluster and Analyze Your Data: Don’t just look at individual failures. Use embeddings to cluster agent traces to find systemic patterns in your data. This is the most effective way to debug and identify areas for improvement (00:36:59).
Engineer Your Tools Thoughtfully: Provide your agent with a well-defined set of tools. For example, instead of one generic search function, offer both a broad search tool and a specific get_document tool. Clear descriptions help the agent choose the right tool for the job (00:37:31).
The Outer Loop of Context Engineering: Continuous Improvement and Evaluation
We wrapped up by thinking through the future of what this work looks like and Jeff distinguished between two loops of context engineering:
The Inner Loop: Figuring out what information to put into the context for a single task, right now.
The Outer Loop: Building systems that get better at filling the context over time.
It’s both figuring out what do I put into context this time. That’s the inner loop. And then it’s how do I get better at context filling over time. And that is the outer loop.
— Jeff Huber, 00:44:19
The long-term challenge is building the “machine that builds the machines“ (00:44:02): systems that can learn from feedback and continuously improve their performance. This is crucial for moving from 90% reliability, which might be acceptable for an internal tool, to the 99.9%+ reliability required for user-facing products.
However, agent evaluation remains a largely unsolved problem (00:40:22) LLM-as-judge is not a panacea, and manual labeling is brittle and expensive. For now, breaking down complex tasks into highly defined, measurable workflows is a practical approach for achieving production reliability, even if the long-term goal is more autonomous agents.
Key Takeaways
Agentic search is the new paradigm: AI is moving from answering simple queries to performing complex, multi-step research on behalf of users.
Context engineering is the central job: Building reliable agents requires a disciplined approach to curating the information fed to the model, focusing on precision over sheer volume.
Large context windows are not a silver bullet: Performance degrades due to “context rot,” and practical applications are limited by high cost and latency.
The “agent harness” is critical: An agent’s true capabilities are defined by the tools, sub-agents, and environment you provide for it.
Focus on the outer loop: The most durable advantage will come from building systems that allow agents to learn and improve over time.
👉 This was a guest Q&A from our November cohort of Building AI Applications for Data Scientists and Software Engineers. It’s a live cohort with hands on exercises and office hours. Our final cohort starts March 9. Here is a 25% discount code for readers. 👈
Jeff and his team at Chroma are also kindly sponsoring our final cohort with $250 in Chroma Cloud credits for all students. That’s part of $1,300 of credits everyone gets in state-of-the-art compute and AI tooling credits: we hope you come build with us!